DB Roll-Out mit integriertem Configuration Management
Inhalt
- Datenbank-Schema Versionen
- Verfügbarkeit - Wartungsfenster - Zero Downtime
- Unterschiedliche DBMS Provider
- Lösungsansätze für optimierte Rollout-Verfahren
- Systemspezifikation für eine Anforderungs-Umsetzung im Unternehmenskontext
- Zu unterstützender Workflow
- Funktionalität und Priorisierung
- User Management: Authentifizierung und Autorisierung
- Registrierung von Servern und Schemata, Konfiguration
- Erstellung von Lieferpaketen
- Delta-Analyse und Skript-Generatoren
- Roll-Back / Undo von Lieferpaketen
- HA-Unterstützung bei der Erstellung von Lieferpaketen
- Roll-Out von Lieferpaketen
- On-Flight-Test
- Review von Lieferpaketen
- Inventar-Report
- Auditing
- Nicht-Funktionale Anforderungen
- Systemumgebung und Kontext: Schnittstellen
- Fazit: Problemlösung und Umsetzungsstrategie
Datenbank-Schema Versionen
Stellen Sie sich die Situation vor: In einem Unternehmen arbeiten viele Entwickler an firmenspezifischen Datenbanken. Die Applikationen setzen bestimmte Funktionen und Datenobjekte in Datenbanken voraus. So mögen mehrere getrennte Datenbanken für unterschiedliche Anwendungen existieren. Einige Anwendungen benutzen die gleiche Datenbank-Instanz, vielleicht das gleiche Schema, andere Anwendungen arbeiten in getrennten Schemata, aber auf der gleichen DB-Instanz, wieder andere benutzen übergreifend mehrere DB-Instanzen. Alle Anwendungen aber werden weiter entwickelt ... und benötigen jeweils Anpassungen an den jeweiligen DB-Schema-Objekten. Die Änderung werden über Deployments oder Roll-Outs geliefert und installiert. Diese unterliegen besondern Freigaben und Verwaltungsprozessen.
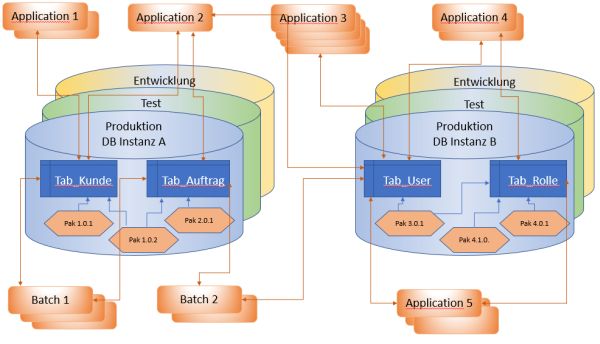
Es wird erkennbar: Das kann schnell unübersichtlich werden. Es ist nicht mehr hinreichend, wenn man eben einfache DB-Scripte entwickelt, und diese dann irgend wie einspielt. Ohne minutiöse Verwaltung wird daraus schnell ein heilloses Chaos.
Insgesamt handelt es sich um Fragen des Configuration Management (CM) die auch in der IT Infrastructure Library (ITIL) adressiert sind. Der Ansatz des CM legt den Fokus auf eine methodische Durchdringung beliebiger Configuration Items (CIs), die ihrerseits in einer Configuration Management Database verwaltet werden. Die spezielle Problematik der Verknüpfung von Verwaltungsprozessen und der technischen Durchführung von DB Roll-Outs genau dieser Prozesse wird zumeist nicht beachtet. Durch fehlende Integration entstehen aufwendige und schwierig handhabbare Situationen.
Im CM von Systemen ist zumeist die Anwendung im Fokus. Z.B. der Roll-Out eines WAR-Files. Im Kontext der DB sind diese Aspekte, abgesehen vom Build-Prozess, eher technisch trivial und nur als Anhängsel wie ein Lieferpaket zu betrachten: Ein War-File wird auf einen Server gepackt und die Anwendung neu gestartet, bzw im Blue-Green-Deployment entsprechend umgeschaltet.
Die technische Komplexität gerade von DB-Lieferungen hängt damit zusammen, dass sich ein Geflecht von einzelnen Komponenten in der Produktion wieder findet, das eben nicht einfach durch eine Komplett-Version ersetzt werden kann. Zumeist kann einem Schema oder DB-Instanz keine eindeutige Version mehr zugeordnet werden, sondern einer Kollektion von versionierten Paketen. Zugleich müssen Daten als das zu bewahrende Asset gegen Verlust, Zerstörung und Missbrauch geschützt werden und die Verfügbarkeit der Anwendung so wenig wie möglich eingeschränkt werden. Unten findet sich das Konzept zu dem noch nicht existierenden Tools DB-Rollout-CM.
Einige Details und Fragen
Jeder Lieferstand der Datenbank-Struktur ist als Zustand zu verstehen, dem man eine Versionskennung auf Objektebene geben kann:
- Inventar: Welche Tabellen existieren, und welche Spalten mit welchen Eigenschaften sind vorhanden? ... ebenso Views, Indexes etc.
- Welche Stored Procedures, Trigger und Config Data existieren in welcher Version?
- Welche Zugriffsrechte für Applikationen und User bestehen.
- Time-To-Market ist ein wichtiges Kriterium. Es kennzeichnet die Handlungsfähigkeit von Entwicklungsprozessen und gilt nicht nur für externe Verkaufsprozesse, sondern auch für die Erledigung interner Anforderungen. Eine hohe Reaktionsgeschwindigkeit kann nur dann erreicht werden, wenn alle Prozessglieder keine unnötigen Verzögerungen verursachen. Darum sind kurze Rollout-Zyklen anzustreben. Die gilt im Besonderen für Agile Entwicklungen.
Roll-Out Ebenen
In der Regel bestehen mehrere Ebenen der Datenbanken.
- Auf Entwicklungsebene werden die jeweils die neuesten Datenobjekte und Prozeduren entwickelt und getestet. Teilweise Parallel für unterschiedliche Teilbereiche.
- Für fachliche Tests bestehen ggf. mehrere Testinstanzen. Hier werden ggf. neue Releases von Dritten vor Inbetriebnahme getestet. Ggf. gibt es auch hier eine Hierarchie, die Customer Acceptance Tests unterstützt.
- Letztlich ist in einem Produktionbetrieb die Anforderung, dass diese möglichst stabil ohne Datenverlust und Ausfallzeit zu Verfügung steht.
Roll-Out Pakete und Repositories
Es hat sich bewährt, Installationen in versionierten Lieferpaketen vorzunehmen. Diese sind jeweils in Freigabeverfahren auf die entsprechenden Instanzen zu migrieren ein Paket kann aus einer Objektänderung bestehen oder aus Hunderten von Schemaobjekten, Tabellen und Prozeduren. Dieses Paket setzt ggf. bestimmte Zustände / Versionen der DB voraus. Auch ist die Reihenfolge der Paket-Installationen nicht immer trivial, denn ein komplexes Pakte kann bereits im Test sein, wenn eine Fehlerkorrektur im nachhinein dazwischen geschoben wird, und damit die Voraussetzungen verändert. Wurde die Voraussetzungsprüfung aber zum Zeitpunkt des Entwicklungsende definiert, ist sie bei Produktivnahme so nicht mehr gültig.
Parallel sind Anwendungsversionen (Dialoganwendungen, Batchanwendungen, Webservices) auszurollen. Manchmal sind parallel mehrere Versionen einer Anwendung aktiv, die sich aber dennoch eine Datenbasis teilen. Kompatibilität zu diesen Anwendungsversionen ist ein wichtiges Thema. Eine Schemaänderung darf nicht eine noch in Betrieb befindliche Anwendung stören. Eine Empfehlung hier ist, dass DB-Änderungen abwärts-kompatibel sein sollten und im Vorlauf vor Applikation-Deployments statt finden. Das allerdings kollidiert u.U. mit engen Zeitplänen - im Besonderen, wenn das mit vereinbarten Wartungsfenstern zu tun hat.
Lieferpakete können als Kollektion von Dateien gedacht werden, die sich in einem bestimmten Kontext in einem Roll-Out installieren lassen und Rollout-Objekte erzeugen oder verändern. Z.B. als ein TAR/GZ file, dass über ID mit Versionskennung identifizierbar ist. Nicht zu verwechseln mit PL/SQL-Packages, die Datenbank-Objekte sind.
Lieferpakete sollten in Repositories abgelegt werden oder direkt in Versions-Control-Systemen wie einem SVN-Repository auf Objekt-Ebene mit Label / Tag versehen werden. Es hat einen gewissen Charme, nur die in einem Version-Control-System eingecheckten Komponenten durch das Verfahren garantiert zu Auslieferung zu bringen. Aber es ist ebenso hinreichend, das Lieferpaket in einem zentralen File-Repository abzulegen. Wenn sich die Rollouts stets aus diesem Repository bedienen, ist sichergestellt, dass die Installation exakt die gleiche Grundlage hat und vor Manipulationen geschützt ist. Zudem ist damit die Revisionssicherheit verfahrensbedingt gesichert.
Meist ist die Abhängigkeit von Lieferpaketen zu definieren und automatisiert zu überprüfen: Pakete dürfen nur installiert werden, wenn bestimmte andere Pakete vorher erfolgreich installiert wurde, bzw. dürfen nicht installiert werden, wenn bestimmte andere Pakete Installiert wurden. Durch Folgelieferungen können Pakete durch andere ersetzt werden, wobei die ursprünglichen Pakete nicht mehr ausgerollt werden sollen.
Paket- und Objekt-Inventar
Mit dem Rollout verändert sich offensichtlich das Paketinventar der DB-Instanz. Daran geknüpft ist das Objektinventar. Unter Objekt wird hier nicht nur das klassische DB-Objekt wie Tabelle, Index, View, Stored Procedure etc. gedacht, sondern auch das Zugriffsrecht (Grant) und eine funktionale Datenlieferung, z.B. für eine Konfiguration.
Einige Rollouts überschreiben wiederum andere, so dass der Zustand auf Objektebene nicht immer trivial zu ermitteln ist. Die Katalog-Funktionen der Datenbanken liefern oft wesentliche Hilfen zur Inventarisierung, sind aber für die vollumfängliche Darstellung unzureichend. So ist der Zustand einer Tabelle meist mit einem gewissen Aufwand ermittelbar, jedoch kaum die dazu gehörige Lieferversion und die Reihenfolge, der Änderungen, die zu diesem Zustand führten. Lediglich bei einigen Objekttypen, die auch Kommentare abspeichern, kann die Objektversion transparent fortgeschrieben werden. Noch weniger ist der Dateninhalt eines Konfigurationseintrages im Catalog ermittelbar, sondern nur durch die aufwendige Analyse der Daten. Eine Lösung ist die automatische Registrierung der Objektversion, die ein geeignetes Tool leisten kann.
Um Entscheidungen für weitere Rollouts zu treffen oder die Analyse von Fehlern zu erleichtern, ist der einfache und transparente Durchgriff auf das Inventar unter Umständen entscheidend. Oft werden aufwendige Analysen im Fehlerfall durchgeführt, nur um schließlich zu erkennen, dass ein erwartetes Rollout nicht durchgeführt worden war. Eine übersichtliche Darstellung kann hier wesentlich den Aufwand der Recherche reduzieren.
Vor allem aus der Umstellung bestehender Datenbanken ist das Gewinnen von Inventarinformationen nicht trivial. Ein Weg zur Erzeugung eines Paket-Inventar kann sein, dass die bereits installierten Pakete manuell erfasst werden, neue Pakete aber mit dem Lieferverfahren automatische Inventareinträge erzeugen.
Der Weg zum Aufbau eines Objektinventars ist nur teilweise aus vorhandenen Verfahren möglich. So kann z.B. aus einem DB-Catalog-Eintrag eine textuelle Darstellung generiert werden. Z.B. kann eine Text zu Tabelle, samt Column-Definition, Constraints und Indexes erstellt werden. Dies kann mit einer MD5 Checksum versehen werden. Finden sich diese Objekte auch in anderen DB-Instanzen, so kann anhand der MD5 Checksum festgestellt werden, ob die gleiche oder andere Versionen vorliegen.
Rollen und Verantwortlichkeiten
- Datenbank-Entwickler erstellen die Schemaobjekte, Stored Procedures, dazu erforderlich Skripts, Konfigurationen und letztlich Lieferpakete. Er ist für Entwicklertest, sowohl der Funktionalität der Scripts als auch der Lieferpakete verantwortlich. Je nach Abstimmung verantwortet er auch Roll-Outs in Testumgebungen.
- Tester verantworten die Tests in den entsprechenden Testumgebungen. Er verantwortet Produktionsfreigaben. Je nach Abstimmung verantwortet er auch Roll-Outs in Testumgebungen.
- Configuration Manager (CMgr) haben die Prozessverantwortung und plant die Inbetriebnahme. Dies kann nach Applikation aufgegliedert sein, oder zentrale Funktion haben. Je nach Abstimmung verantwortet er auch Roll-Outs in Produktionsumgebungen.
- Datenbank Administratoren (DBA) unterstützen die technische Bereitstellung und sind für die Infrastruktur, einschließlich Passworten zuständig. Je nach Abstimmung verantwortet ein Datenbank Administrator Roll-Outs in Produktionsumgebungen.
- Die Viewer-Rolle dient zum recherchieren der Einträge, ohne jedoch funktionale Änderungen vornehmen zu können.
- Auditoren prüfen die Compliance zu Standards, z.B. PCI DSS. Dazu benötigt er völlige Transparenz zu den eingesetzten Verfahren und der Dokumentation der Durchführung. Über einem Viewer hinaus können sie Prüfberichte ablegen.
Rollengliederungen sind nicht nur unternehmensspezifisch unterschiedlich, sondern richten sich auch nach den technischen und organisatorischen Besonderheiten des Roll-Out Verfahrens.
Dokumentation, technische Integration und Freigabeverfahren
Neben einer übersichtlichen und revisionssicheren Dokumentation der Änderungen, Versionen und Freigabeverfahren, die unabdingbar sind, gibt es oft weitere Randbedingungen:
- Es ist wünschenswert, Freigabeprozesse, technische Rollouts und Dokumentation / Reports integriert zu verwalten, nicht durch separate Prozesse manuell zu synchronisiseren. Dies senkt Arbeitsbelastung, erforderliches Spezialwissen und Fehleranfälligkeit.
- Wer ist autorisiert, Änderungen einzuspielen? Ist ggf, ein Vier-Augen-Prinzip sicherzustellen?
- Wie kann sichergestellt werden, dass die Verfahren auditierbar im Kontext von Compliance Anforderungen sind, z.B. für eine PCI-Zertifizierung?
- Wie kann eine Dokumentation bei ggf. auftretenden Fehlern eine schnelle Abhilfe bewirken? Kann die Zeit, die ein Rollout benötigt, festgestellt werden, um ggf. Rollout-Entscheidungen daran zu orientieren?
- Werden Undo-Funktionen unterstützt? Merke: Der Ausgangs-Zustand zum Entwicklungszeitpunkt ist unter Umständen nicht der, der zum Deployment-Zeitpunkt vorliegt. Ein Roll-Back sollte nicht zu dem alten Entwicklungs-Zustand erfolgen, sondern zum Produktion-Zustand vor der Änderung. Das Zeitfenster für ein Undo ist zumeist eng begrenzt, denn wenn auf Basis der Änderungen weitere Transaktionen durchgeführt wurden, droht ein Datenverlust beim Einspielen eines Backup.
Delta-Analyse und Skript Generatoren
Einige Tools werben mit dem Konzept, dass die Änderungen automatisch detektiert werden und aus dem erkannten Delta Scripts generiert werden. Dies mag vor allem im Umfeld einfacher Umgebungen ohne DB-Entwickler und detailliertem Freigabe-Management sehr attraktiv sein. Z.B. wenn Anwendungsentwickler neue DB-Objekte benötigen, so erzeugen sie sich diese Tabellen - ohne sich über die Rollout-Verfahren Gedanken machen zu müssen. Das Tool sorgt dann für eine automatisierte Lieferung.
In größeren Umgebungen, in denen an parallelen Entwicklungen gearbeitet wird, erscheint eine Versionspflege dieser Art wenig überzeugend: Die Kontrolle, welche Objekte in welcher Version freigegeben werden, wie ein Test auf einer definierten Version erfolgen kann, weckt Zweifel an der Nützlichkeit eines Delta-Verfahrens. Ebenso, wie komplexe und DBMS-produktspezifische Verfahren zugleich Objekte wie Trigger, Stored Procedures, Constraints, spezialisierte Datentypen und Konfigurationsdaten sicher behandelt werden können.
Verfügbarkeit - Wartungsfenster - Zero Downtime
Anwendungen sollten weitgehend verfügbar, also in Produktion sein. Das gilt immer mehr für Dialoganwendungen und Services, die früher mit Batch-Anwendungen konkurrierten, nun aber meist parallel laufen. Batch-Prozesse zu Daten-Im- und -Export, Reporting, Datensicherung und Reorganisation werden oft zeitgesteuert, aber auch in Abhängigkeit von anderen Ereignissen automatisiert eingeplant. Hochverfügbarkeit - High Availability (HA) - erfordert besondere Maßnahemen und Aufwand.
Adressiert werden Sicherung gegen eine Downtime wegen:
- Ungeplante Ausfälle wegen Hardwäre fehlern oder software-Fehlern
- Geplante Ausfälle wegen Betriebssystem- oder DBMS-Patches
- Geplante Ausfälle wegen Schema-Upgrades
- Geplante Ausfälle wegen Datenänderungen
Hier sind im Besonderen die letzten beiden Bedarfe im Fokus, aber eine HA-Infrastruktur, die wegen der ersten beiden Verfahren eingerichtet wurde, kann die Anforderungen für Rollouts beeinflussen. Wird im Verbund nach einer HA-Lösung gesucht, die alle Anlässe abdecken soll, so sind auch die anderen Anforderungen zu berücksichtigen. Einen guten Überblick der Problematik bei Oracle liefert Yavor Ivanov
Die Anforderung an die Verfahren / Schema-Migration-Tool sind im Kontext der Verfügbarkeit der Anwendungen sind offensichtlich. Es muss der Prozess hinsichtlich der Einschränkung der Verfügbarkeit je nach Variante bekannt sein und ggf. technisch unterstützt werden. Verwaltungselemente sind die Fragen nach Unterbrechungen, deren Zeitdauer, Benachrichtigung von Nutzern oder Kunden, Vereinbarungen von Wartungsfenstern uvm. Ein Verzicht auf Unterbrechungen wäre, soweit möglich, sehr attraktiv. Es kann auch einen wesentlichen Unterschied machen, ob eine Betriebsunterbrechung sich über Stunden hinzieht, im Bereich weniger Sekunden ist oder vollständig vermieden werden kann.
Batch-Prozesse sollten in in der Regel nicht während Schema-Migrationen laufen, auch wenn mit Blue-Green-Deployments eine grundsätzliche Verfügbarkeit gegeben sein mag. Auch bei lesenden Prozessen kann es zu kurzzeitigen Ausfällen kommen, zumindest liegt im Batch ein gewisser Workload an, der den Migrationsprozess belastet. Da bei einer Vielzahl von möglichen Batchprozessen nicht immer klar ist, ob alle laufenden Batch-Prozesse beendet wurden, bzw dass während der Migration nicht neu gestartet wird, sind Verfahren zur Überwachung und Steuerung zu unterstützen, die eine Kollision der Prozesse vermeiden.
In manchen Fällen wird ein unterbrechungsfreier Betrieb ohne Wartungsfenster / Downtime auch für die Schema-Migration erforderlich. Z.B. bei kritischen Anwendungen, bzw. wenn entsprechende Service-Level-Agreements (SLA) geschlossen wurden. Dies gilt im Besonderen, wenn keine laufende Transaktion unter keinen Umständen verloren gehen darf, auch nicht abgebrochen werden soll. Denn eine kurzzeitige Störung im Online-Betrieb mag u.U. akzeptabel sein, oder auch nicht. Stellen wir uns vor, dass eine Unterbrechung im Sekundenbereich zu einer betriebsruhigen Zeit statt findet. Möglicherweise bleiben Störungen im Ablauf dann unbemerkt, noch treten sie überhaupt in Erscheinung. Dagegen ist der Aufwand, eine uneingeschränkte Verfügbarkeit auch bei Sekunden-Ausfällen sicher zu stellen, zum Teil enorm.
Ein Bespiel: Wird eine Spalte in einer Oracle-DB hinzugefügt, werden die Stored Procedures, Views und Trigger, die auf diese Tabelle zugreifen, invalide. Eine Anwendung, die auf invalide Objekte zugreifen will, läuft auf einen Fehler - auch wenn das entsprechende Objekt in Sekundenbruchteilen automatisch rekompiliert wird. Führt aber die Anwendung in diesem Fall ein für den Anwender unsichtbares und automatisiertes Retry durch, wird keine Unterbrechung erkennbar.
Hier eine weitere Einführung in die Problematik.
Konzeptionelle Ansätze zur Lösung finden sich z.B. bei Martin Fowler Blue-Green-Deployment /
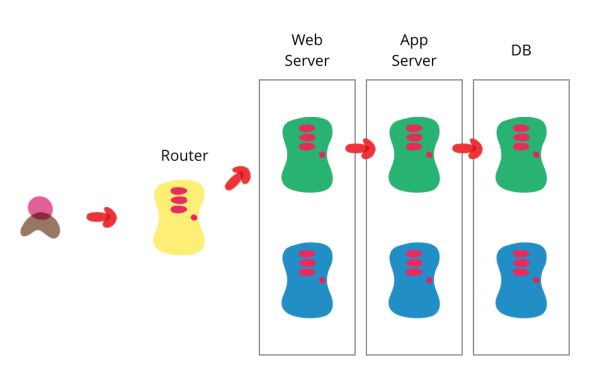
Kurzdarstellung in der CW oder bei Anbietern von RDBMS ...
Oracle HA Support
Oracle liefert HA Unterstützung mit Data Guard,
bzw. in einer verbesserten Version mit Active Data Guard.
Aber auch Oracle sieht Einschränkungen, dass ein vollständig unterbrechungsfreier Betrieb nicht immer gewährleistet werden kann. Man spricht hier von der Minimierung der Downtime. Zudem sind konzeptionelle
Das Problem ist die Umschaltung. Wenn eine DB-Instanz (Green) von der anderen (Blue) abgekoppelt wird, um diese mit einem Rollout zu verändern, werden in der Zwischenzeit Transaktionen durchgeführt. Da auf Green nur abgeschlossene Transaktionen sind, ist diese Umschaltung problemlos.
Das Problem entsteht bei der Umschaltung von Blue auf Green. Im Idealfall wird die laufende Transaktion auf Blue noch parallel weitergeführt und abgeschlossen. Neue Transaktionen werden bereits auf Green gestartet. Schließlich wird das Redo-Log der alten Instanz aus dem Zeitfenster der Abkoppelung auf der neuen Instanz eingespielt.
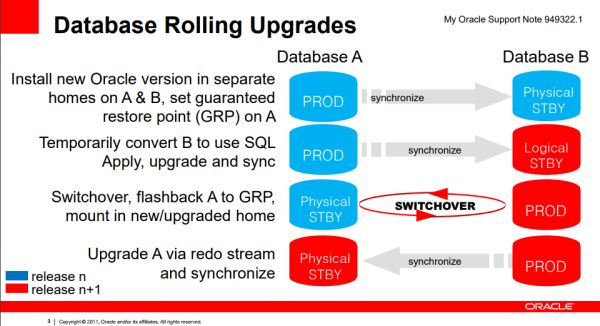
Einige der Transaktionen / Datenänderungen lassen sich auch danach wieder synchronisieren, aber je nach Schemaänderung ist dies u.U. nicht automatisiert möglich, denn die Zielstruktur auf Green ist nicht mehr mit der Ausgangsstruktur identisch. Mancherlei einfacher ist ein Upgrade der RDBMS-Software, ein weiteres Problem des unterbrechungefreien Betriebs. Hier brilliert der Ansatz des Blue-Green-Deployment. Denn es finden keine Schemaänderungen statt, aber eine Downtime von u.U. mehreren Stunden kann vermieden werden. Dennoch: Trivial ist auch das nicht, denn auch wenn keine Schemaänderungen geschehen, ist das Einspielen der Redo-Logs zwischen den Versionen nicht immer gewährleistet und sollte vorher getestet werden.
Ferner ist bei einer Aufteilung von DB-Entwicklung und Oracle Administratoren mit Abstimm-Problemen zu rechnen. Denn Admins lassen sich in die Konfiguration von DataGuard und heiklen Spezialanwendungen nicht gerne hineinreden.
Glücklicher Weise hat Oracle weitere HA Supportangebote:
Oracle Edition Based Redefinition (EBR)
Hierbei geht es nicht um eine vollständige Parallelisierung der Datenbank, im besonderen nicht der Daten, sondern um die parallele Existenz von Code-Elementen in Editions, also Packages, Views etc. Dabei können begonnene Transaktionen mit einer alten Version noch weiterlaufen und abgeschlossen werden, während neue Transaktion parallel mit der neuen Version arbeiten. Allerdings ist einiges zu beachten im Kontext dieser Umschaltung
Dieses Feature ist ab Oracle 11g Release 2 verfügbar - und zwar im Kern ohne kostenpflichtige Option. Eine Beschreibuung findet sich in der Artikelserie von Tom Kyte
- A Closer Look at the New Edition
- Edition-Based Redefinition, Part 2
- Looking at Edition-Based Redefinition, Part 3
Ein gute Referenz für häufig benötigte Befehle: hier
Daraus die Problembeschreibung, wenn während des laufenden Betriebs diese Objekte aktualisiert werden sollen:
Kochbuch / Vorberitungen: Der System User muss folgendes ausführen (Beispiel)
ALTER USER pre_stat ENABLE EDITIONS; CREATE EDITION verblue AS CHILD OF ora$base; GRANT USE ON EDITION verblue TO pre_stat; GRANT ALTER SESSION TO pre_stat;
Die GRANTs müssen natürlich auch weiteren Usern, die auf diese Objekte zugreifen sollen, zugewiesen werden.
Erst dann kann hier im Beispiel-Schema Prestat mit Editions gearbeitet werden.
Einige Erfahrungen:
ALTER USER schema_user ENABLE EDITIONS;
ist kritisch und wirft Fehler, wenn sich andere, nicht editable objects auf potentielle Kandidaten beziehen. Synonyme auf editable Schemaobjects (Package, Views etc.) verhindern das enable. Synonyme auf non editables (z.B. Tabellen) bleiben unkritisch.
Und auch danach: Wenn ein User, der nicht für Editions zugelassen ist, ein Synonym auf ein editionabel object setzen will, bekommt er die Meldung:
[Error] Execution (7: 1): ORA-38818: Ungültige Referenz auf editioniertes Objekt PRE_STAT.PC_PRE_STAT
Schemakopien und Blue / Green Deployments
Auch ohne spezielle Software-Komponenten zu verwenden, bzw. RDBMS, kann das Konzept für Schema-Migration u.U. Anwendung finden: Einzelne Objekte / Tabellen oder komplette Schemata können gespiegelt werden (Cloning, Phase Null). Dies erfordert keine eigene DB, aber genügend Ressourcen / Plattenplatz. Welches Verfahren zum Einsatz kommt, bleibt der jeweiligen Applikation geschuldet. Wenn z.B. die Applikation mit einer einfachen Konfigurationsänderung auf ein anderes Schema umgestellt werden kann, ist es problemlos. Wird das über ein Schema Rename gemacht, hat man noch immer minimale Betriebsunterbrechungen bei Umschaltung. Ansonsten gelten die weiteren Anmerkungen:
Grundsätzliches zum Spiegelfechten
Folgende Betrachtungen gelten dann, wenn sich besondere Verfahren wie EBR nicht zum Einsatz kommen:
Verfahren, die den unterbrechungsfreien Betrieb auch bei Schema-Rollouts in einem Produktionsbetrieb sicher stellen wollen, müssen sehr sorgfältig alle Fehler-Möglichkeiten vorher sehen. ggf. sind auch mehrere Synchronisations-Phasen erforderlich:
- Aufbrechen des Spiegels / Herstellen einer abgekoppelten Instanz (Green)
- Rollout auf der abgekoppelten Instanz
- Kurzer Funktionstest auf Green möglich
- Synchronisation mit den zwischenzeitlichen Transaktionen - bis hier kann das Rollout noch abgebrochen werden, ohne irgend eine Änderung zu aktivieren. Allerdings kann hier eine besondere Schwierigkeit liegen, denn die einzuspielenden Transaktionen können sich auf geänderte Schema-Objekte beziehen, die eine Zwischenaufbereitung der Transaktionen erforderlich machen. Selbstredend erfordert das generiertes SQL, das mittels Script an die geänderte Struktur angepasst werden muss. Das Replikationstool müsste dann die logischen Transaktionen ausgeben. Die meisten Werkzeuge generieren hier aber einen binären Stream, der dafür ungeeignet ist. Oracle Data Guard soll auch die logische Replikation beherrschen, bei seinem Pendant bei PostgreSQL Streaming Replication ist davon nicht die Rede. Dort wird auf den Ansatz Pgpool-II verwiesen, der allerdings das Problem der Rolling Upgrades nicht detailliert adressiert.
- Test der Re-Synchronisation.
- ggf. wiederholen der letzten Schritte, damit nur ein sehr kleines Zeitfenster übrig bleibt, in dem die laufenden Transaktionen von Blue noch nicht auf Green sind. Denn wenn eine Transaktion abgeschlossen wird, kann in einer Folgetransaktion darauf Bezug genommen werden. Es wäre dann noch immer nicht voll befriedigend, wenn die kritische Transaktion verspätet wirksam wird, aber der Folgetransaktion nach der Umschaltung zunächst nicht bekannt ist.
- Umschalten der Produktion von Blue auf Green.
- Finale Synchronisation von Blue nach Green.
- Rollout der Änderungen auf dem abgekoppelten Blue.
- Synchronisation / Aktivierung des Spiegels auf Blue
Es ist eine Herkules-Aufgabe, die ein entsprechendes Schema-Migrationsverfahren mit technischer Unterstützung erfordert.
Eine Variante, die auch ohne Blue-Green-Deployment und Data Guard auskommt, wäre z.B. die Nutzung bei Oracle von DBMS_Redefinition. Hierbei lassen sich auch komplexe Änderungen soweit in der aktiven Instanz vorbereiten, dass nur eine kurze Umschaltzeit erforderlich ist, in dem der Betrieb nur eingeschränkt möglich ist. Wenn die Applikation die DB-Zugriffe puffern kann, würde die Anwendung, bzw. der Anwender nahezu keine Unterbrechung fest stellen. Im Besonderen ist dies bei reinen Datenänderungen und bei einfachen Schema-Upgrades sinnvoll, wenn der komplexe Overhead eine Data Guard Rolling Upgrade nicht erforderlich ist.
Allerdings hilft ein Verzicht auf eine gespiegelte Instanz nicht bei der Änderung der DBMS-Software. High Availablity sollte auch für diese Fälle eine Lösung bieten. Darum sind Spiegel-Lösungen deutlich attraktiver. Ggf. ist eine Kombination aus beiden Ansätzen sinnvoll.
Ein HA-Wunsch-Szenario beim Schema-Upgrade mit Tool-Unterstützung im Kontext von Blue-Green-Deployments:
Ein Upgrade hat eine erwartete Laufzeit von 2 Stunden. Es wird zur automatischen Ausführung ohne Überwachung für 03:00 eingeplant:
- Automatisch wird der Spiegel aufgebrochen und skriptgesteuert wird auf Green die Änderung ausgeführt, während auf Blue die Produktion weiter läuft.
- Die automatische Re-Synchronisation der Transaktionen von Blue läuft ab 05:30 erwartete 20 Minuten.
- Zum Schichtbeginn um 6:00 kommen die Mitarbeiter und inspizieren die Log-Files und die Systeme. Sind keine Probleme aufgetreten, kann eine aktualisierende Synchronisation von Blue auf Green erfolgen und eine Umschaltung der Produktion von Blue auf Green durchgeführt werden. Gab es Probleme, kann der Vorgang verlustfrei abgebrochen werden. Eine nachgelagerte Analyse kann einen neuen Versuch ermöglichen.
- Die Umschaltung kann ggf. völlig ohne Transaktionsverlust geschehen. und eine Finale Synchronisation von den Resttransaktionen zwischen der letzten Synchronisation und der Umschaltung nachgezogen werden - das upgegradete System steht auf Green zur Verfügung.
- Nun kann auch Blue nachgezogen werden und der Spiegel für die Hochverfügbarkeit wieder aufgebaut werden.
Unterschiedliche DBMS Provider
Viele Unternehmen versuchen, möglichst mit einem Hersteller von Datenbank-Management Systemen (DBMS) zusammen zu arbeiten, oft Oracle. Die Entscheidungen, welches DBMS betroffen ist, ist für die Migration von Schemaversionen i.d.R. vorgegeben. Hier wird aber im Wesentlichen auch die technische Aufgabe vorgegeben, wie Schemaänderungen geschehen können.
NoSQL Datenbanken sind meist schemalos und haben eine Replikation im Grundumfang. Roll-Out Prozesse sind hier meist einfach und unproblematisch.
Weit komplexere Anforderungen stellen transaktionsbasierte relationale DBMS (RDBMS): Wird Replikation (Spiegelung) vom DBMS unterstützt und eingesetzt? Welche Leistungsmerkmale unterstützt die Replikation? Z.B. ist es ein deutlicher Unterschied ob bei Oracle (passive) Data Guard oder Active Data Guard (S.9 ff) eingesetzt wird. Data Guard ist im Umfang der Enterprise Edition bereits vorhanden, Active Data Guard ist eine lizenzpflichtige Option. Beliebter werden auch Systeme wie PostgreSQL / GreenPlum, die diese Merkmale ohne die hohen Lizenzkosten wie bei Oracle bereit stellen.
In Unternehmen gibt es meist eine Haupt-Linie, in der Unternehmensdaten verwaltet werden, oder so stark getrennte Bereiche, dass an gemeinsame Verfahren nicht gedacht wird. Nicht selten müssen aber Lösungen unterschiedlicher DBMS-Anbieter betrieben werden.
Oft aber sind die Grundfunktionen von Marktüblichen Tools ähnlich: Entweder, es wird über JDBC-Treiber die jeweiligen Datenbanken angesprochen, oder es gibt jeweils spezifische Skript-Lösungen, die aber über gemeinsame Verfahren gesteuert werden. Problemlos ist aber ein Multi-Plattform Betrieb meist nicht.
So können enorme Probleme entstehen, wenn herstellerspezifische Eigenschaften, die ggf. auch von der Version des DBMS abhängen, verwendet werden, nicht aber vom Migrationstool unterstützt werden. Die Annahme, dass der Tool-Anbieter stets eine vollständige und sichere Unterstützung aller erforderlichen Merkmale garantiert, kann sich als trügerisch erweisen. Gerade größere Unternehmen werden darum auf Open Source Lösungen oder auf Eigenentwicklungen vertrauen, damit man im Zweifel handlungsfähig bei Wartung in Eigenregie bleibt.
Lösungsansätze für optimierte Rollout-Verfahren
Unternehmenslösungen
Schema-Migration wir oft durch unternehmensintern Verfahrensanweisungen geregelt. In rein organisatorischen Verfahren kommen Konventionen und Regeln zum Einsatz, die die einige Probleme zu vermeiden helfen. Es muss aber bereits früh zu Organisationshilfsmitteln gegriffen werden: Organisationshilfen, z.B. Excel-Sheets, Wikis oder spezialisierten CM-Anwendungen.
Die jeweiligen Scripts werden oft durch Script-Frameworks zur Ausführung gebracht. Aber alle Lösungen haben ihre Grenzen und erfüllen manche Anforderungen nur bedingt oder sehr aufwändig und Fehleranfällig.
Ausgewachsene Lösungen, die den o.g. Bedarf weitgehend abdecken, sind für größere Unternehmen durchaus möglich. Entscheidungen zur Entwicklung und Wartung dieser Verfahren sind jedoch mit finanziellen Risiken belastet, die oftmals eine positive Entscheidung verhindern. Darum finden sich in der Praxis auch bei Konzernen nicht selten nur unbefriedigende Lösungen.
Skript-Generatoren
Einig Tool-Anbieter sind technisch getrieben. Sie entwickeln Verfahren, die einen Delta-Zustand zwischen zwei Schemata-automatisch detektieren und entsprechende Skripte selbstständig erstellt, die den Zustand abgleichen. Dies ist vor allem in Agilen Prozessen mit vergleichsweise geringem DB-Know-How von Interesse, kann aber auch die Entwicklungsprozesse erleichtern und effizienter machen.
Dennoch schwingt die Angst mit: Führt das Toolset zu eingeschränkter Flexibilität und Leistung? Ist die Entscheidungkontrolle über Lieferumfänge ggf. nur eingeschränkt möglich, oder führen Systemfehler gar zu noch größeren Probleme, wenn die Detailprozesse nicht mehr vollständig verstanden werden?
Erfahrene DB-Entwickler haben oft einen Schwerpunkt bei der Entwicklung von Stored Procedures und Optimierungen. Ein rigider aber universeller Rahmen von Schma Migration Tools kann sich als kontraproduktiv erweisen.
Konventionen
Auch im einfachsten Fall wird man um gewisse Konventionen über Prinzipien, Namen und Gliederungen nicht verzichten können. Diese beziehen sich auf Namen von Tabellen, Dateien, Verzeichnisgliederungen und Formatierungen. Z.B. kann eine Konvention sein, dass dann und nur dann ein Fehler benachrichtigt wird, wenn auch ein unerwarteter Zustand eintritt. Oracle selbst liefert dagegen oft Fehlermeldungen, die ignoriert werden können. Die Anforderung der Restart-Möglichkeit einer Objekt-Änderung kann die Durchführbarkeit von entsprechenden Verfahren weitgehend ermöglichen oder verhindern.
Konkrete Ausgestaltungen der Konventionen bildet sich aus dem Wechselspiel zwischen den Verfahren und eingesetzten Tools, andererseits aus gewachsenen Unternehmensstukturen. Letztlich bilden dann die Konventionen ein gewisses Fundament der Migrationspakete. Dies trifft in jeweils unterschiedlichem Maaße für alle Verfahren zu, ob nun mit oder ohne Tooleinsatz. Aber man sollte sich darüber im Klaren sein, dass der Tooleinsatz auch die Anforderung an Konventionen verändert.
Schema-Migrations Tools
Viele Anbieter bieten Datenmigrationswerkzeuge an, die hier allerdings nicht gemeint sind. Manch erzeugen Meta-Sprachen, die die Änderungen an Schemaobjekten erleichtern sollen und ggf. die Erstellung von Delta-Skripts automatisieren. Dies aber trifft oft nicht den oben genannten Bedarf.
Einige Produkte:
- Liquibase Open Source: Apache 2.0 License - Last update: 24.10.2016 . Das System ist um das Konzept des Changelogs herum aufgebaut, in dem die jeweiligen DB-Änderungen beschrieben sind. Dieses kann in unterschiedlichen Formaten eingebracht werden. Mehrere Plugins unterstützen spezifische Merkmale der DBMS. Für Oracle z.B. Materialized Views. Aber es ist nicht erkannbar, ob überhaupt PL/SQL Unterstützt wird.
- Flyway verspricht Unterstützung für continous delivery and zero downtime ... aber in der Dokumentation ist nichts mehr davon zu finden - nur ein Verweis auf ein archtictural Training. Vielmehr scheint es ein ehr einfaches Konzept zu sein, dass eben das Delta aus Create-Scripts ermittelt auf Basis von Lieferversionen. Sicher recht hilfreich in einfachen Umgebungen für single Application DBs.
- DbMaintain Auch hier das Angebot der Automatisierung von Rollouts - - Last update: 20.07.2011
- Phinx speziell für PHP-Anwendungen
Es stellt sich die Frage, ob und wie diese Tools zu dem o.g. Problemfeld passen. Ein Schwerpunkt scheint in dieser Tool-Klasse die technische Automatisierung von Rollout-Vorgängen zu sein, bei selbstständiger Feststellung von Deltas - weniger die revisionssichere Verwaltung im Sinne des Configuration Management von Enterprise-Systemen.
Produkte, die seit Jahren keine Updates erfahren haben, scheinen keine Grundlage zu sein, unternehmenskritische Anwendungen darauf zu entwickeln. Aber die Konzepte können Anregungen liefern, Kriterien zur Beurteilung dritter Lösungen und Eigenentwicklungen bereitzustellen.
Viel mehr scheint es, dass derartige Lösungsansätze wenig geeignet sind, gehobenen Unternehmensanforderungen zu entsprechen und ein ausgefeiltes Release-Management zu unterstützen.
Bedarfsanalyse
Aus der Menge der Möglichkeiten muss der konkrete Bedarf heraus gearbeitet werden. Dabei ist sowohl die Voraussetzung, die bereits gewonnenen Erfahrungen, spezifische Präferenzen und Prioritäten abzuwägen. So ist einerseits der Budgetrahmen und Risiko-Betrachtungen bei einer Verfahrensumstellung mitunter ebenso wichtig wie die Erfüllung essentieller Funktionen. Steht vor allem der ordnungsgmäße Prozess im Vordergrund? oder moderne agile Entwicklungsverfahren? Stehen fachkundige DB-Entwickler zu Verfügung oder muss ein sehr kleines Kernteam den Prozess steuern? Ist die arbeitsteilige Prozessführung wichtig?
Manche Verfahren arbeiten angebotsorientiert: Wenn es ein bewährtes Tool gibt, so mag dieses bereits (einige) Probleme lösen, die man selbst noch nicht erkannt hat, aber dennoch zu erheblichen Problemen führen, wenn man sie nicht analysiert. Andererseits gibt es auch Lösungen, die im konkreten Kontext nicht gebraucht werden, und darum eher unpassend ist. Bei reinen bedarfsorientierten Lösungen, die teilweise auch Nice-To-Have-Features betont, kann die Vorteile konfektionierter Tools nicht nutzen.
Systemspezifikation für eine Anforderungs-Umsetzung im Unternehmenskontext
Im folgenden gehen wir davon aus, dass existierende Toolanbieter keine hinreichenden Konzepte und Features liefern, um den Anforderungen hinreichend zu entsprechen. Darum wird ein hier ein grober Systementwurf geliefert.
Zu unterstützender Workflow
Im Folgenden wird die Hauptlinie eines Roll-Out Prozesses skizziert, die sich im konkreten Unternehmensumfeld genau so, oder auch völlig unterschiedlich darstellen lässt. Beschrieben wird der Workflow anhand des noch nicht existierenden Tools DB-Rollout-CM:
- Ein Entwicklungsauftrag wird erteilt. Dies führt zu einer Identifikation eines zu liefernden Paketes. Dieses wird in DB-Rollout-CM, um eine eindeutige Paket-Version zu erhalten.
- Der DB-Entwickler erstellt das Paket, in dem er die integrierten Verwaltungsfunktionen der Roll-Out-Anwendung von Anfang an nutzt und die entsprechenden Parameter an nur genau einer Stelle einpflegt. Neben dem Lieferpaket werden alle Objekte als Configuration Items (CI) identifiziert. Dies ermöglicht eine klare versionsbezogene Inventarisierung.
- Ergänzend zu den Entwicklertest seiner Objekte ( empfohlen: Unit-Tests mit DbFit diese können über Links mit DB-Rollout-CM verknüpft werden ) testet der DB-Entwickler auch das Roll-Out seines Lieferpaketes mit der Roll-Out-Anwendung auf der Entwicklungsinstanz. Dies ist kein Mehraufwand, denn dieses Rollout funktioniert auf Knopfdruck. Wenn es Fehler gibt, ist es gerade gut, dass dies bereits der Entwickler in seinem Bereich noch beheben kann, bevor größere Zyklen angestoßen werden.
- Schließlich kann eine Freigabe zum Test durch einen Entwickler oder einen Peer nach einem Code Review erfolgen.
- Der Tester kann nach der Testfreigabe per Knopfdruck den Roll-Out auf der ausgewählten Test-Instanz durchführen und die fachlichen Tests durchführen. Unter Umständen kann dieser Vorgang auf anderen Test-Instanzen, oder auf einem Produktions-Klon wiederholt werden.
- Nach Produktionsfreigabe durch den Tester kann der Produktions-Rollout - ggf. zeitgesteuert - geplant und durchgeführt werden.
Zu allen Phasen ist die Dokumentation und Integrität des Prozesses durch die Roll-Out-Anwendung gewährleistet. Eine Autorisierung der Benutzer sorgt für die ordnungsgemäße Abwicklung. Die Protokollierung hilft, ggf. Fehler zu erkennen und zu jeder Phase schnellstmöglich zu beheben.
Funktionalität und Priorisierung
Um diesen Workflow und weitere Zusatzfunktionen wie Auditing und Zero-Downtime zu unterstützen, sind einige Funktionen erforderlich, die im Folgenden beschrieben werden Die Priorisierung hier ist ein Beispiel, wie sie sich aus meinem konkreten Umfeld darstellt. In anderen Kontexten mag man andere Schwerpunkte setzen
User Management: Authentifizierung und Autorisierung
User sind zu authentifizieren um sicher zu gehen, dass nur berechtigte User die jeweiligen Funktionen ausführen können. Es ist hierbei entweder eine interne Passwort-Verwaltung für ein Stand-Alone-System möglich als auch die Anbindung an ein single Signon mit LDAP oder ähnlichem. (Prio 1)
In jedem Fall ist eine interne Userverwaltung erforderlich, die weitere Attribute, wie Rollenzuweisung Mail, Telefon, Vertreter etc. regeln kann. Im Fall einer internen Authentifizierung ist die Funktion zum Zurücksetzen der Passwörter erforderlich. Entweder als Administrator-Funktion, oder zum Generieren eines Einmal-Passworts, dass an die hinterlegte Mail-Adresse gesandt wird. Dies entfällt bei externer Authendifizierung.
Die Autorisierung sollte mit einer internen Rollenzuordnung geschehen. Eine Auslagerung der Rollenzuweisung in eine externe Rollenzuordnung - z.B. LDAP-Attribute - ist möglich, aber weniger transparent. Eine interne Rollenzuordnung kann weit eher bei der Wahl von Vertretern, deren Protokollierung und einiges mehr bewirken. (Prio 2)
Die zuweisbaren Rollen sind wie zumeist oben genannt:
- Datenbank-Entwickler (DBDev) kann Pakete und CI verwalten und Roll-Out auf Entwicklungsplattformen durchführen.
- Tester (QAT) kann Roll-Out in Testumgebungen durchführen
- Configuration Manager (CMgr) kann Inbetriebnahme auf Produktionsplattformen durchführen.
- Datenbank Administratoren (DBA) Bereitstellung der Infrastruktur, einschließlich Passwords für Sysdba, QA und Produktions-Schemata. Auch Roll-Outs in Produktionsumgebungen.
- Die Viewer (VI)-Rolle für Inventory-Reports und Logs.
- Auditoren (AUD) prüfen die Compliance zu Standards
- System Administratoren (SA) Bereitstellung der Programm-Funktionen.
Neben dieser vertikalen Gliederung kann eine horizontale Berechtigung in Erwägung gezogen werden: Verantwortlichkeiten für Schemata oder Bereich können über ein additives Rollenkonzept ermöglicht werden. Eine QAT-Rolle würde dann nicht mehr Zugriff auf alle DB-Instanzen der Test-Klasse ermöglichen, sondern nur diese, die auch gemäß Rollenprofil zulässig sind. Dies Anforderung sollte nur in sehr großen Organisationen bedeutsam sein. Darum hier die Einstufung der Prio 3.
Registrierung von Servern und Schemata, Konfiguration
Alle Server / DB-Instanzen müssen zugreifbar sein. Dies schließt ein, dass Systemzugänge ermöglicht werden (keine Firewall-Blockade, erforderliche Treiber und Passwords) und hinsichtlich der Kategorie (Dev, QA, Prod) abgelegt sind. Passwords werden selbstverständlich verschlüsselt abgelegt. Diese Aufgaben erfordern zumeist die DBA Rolle.
Die zugehörigen Schemata werden identifiziert: Welche Schemata sind mit welchen Zugriffsmethoden auf welchem Server verfügbar? Insgesamt ist es eine Kernfunktionalität - darum Prio 1
Ferner sind Verfahren zu Konfigurieren und programmspezifische Grundeinstellungen vorzunehmen. Dies kann ggf. über eine Ini- oder Conf-Datei geschehen.
Erstellung von Lieferpaketen
DBDev identifizieren die Lieferpakete mit der Erzeugung jener. Die Lieferpakete beziehen sich stets auf ein Schema. Idealer Weise tragen sie einen Schemanamen und eine Versionskennung. Bei der Initialisierung kann somit festgestellt werden, dass die ID eindeutig einem Auftrag, z.B. einem Errorfix oder einer neuen Funktionalität, zugeordnet ist. Ein drei- oder vierstelliges Nummernschema für die Versionskennzeichnung hat sich bewährt. Die letzt Ziffer kennzeichnet die Revision des Paketes. Wenn zum gleichen Thema ein Korrektur oder Erweiterung erfolgt, wird das Vorläuferpaket zumeist vollständig ersetzt.
Ebenso kann hier sehr früh festgehalten werden, was die Voraussetzung dieses Paketes ist, also welche Pakete vorher installiert wurden, und welche nicht vorher installiert werden durften.
Die Ausgestaltung der Komponenten, im Besonderen der Objektskripte, ist zum Einen von den vereinbarten Konventionen und zum Andernen von der Ziel-Infrastruktur abhängig. Wir für einen HA-Kontext ein Lieferpaket erstellt? Ist die Zielstruktur eine Oracle 12c DB -oder doch eine PostgreSQL-Installation? Sind die Scripte für SQLPLUS oder eine anderen Script-Runner zu konzipieren?
Ein benötigtes Feature ist, die Reihenfolge der Schritte festzulegen.
In der Konfiguration von DB-Rollout-CM ist diese Infrastruktur ggf. in mehreren Varianten zu hinterlegen und bei der Anlage der Lieferpakete zu zuweisen.
Ebenso kann eine Versionierung mit einem Version-Control-System wie SVN oder GIT hergestellt werden, in dem die jeweiligen Sourcen abgelegt sind und mittels Tag identifiziert werden (Prio 3). Um aber die Abhängigkeit von Drittinstallationen nicht unnötig aufzublähen, kann die Verwaltung der Sourcen auch in separaten Subsystemen statt finden und die Lieferpakete en Block (tar/gz) in das integrierte File-Repository geladen werden. (Prio 1)
Weiter Stufen der Verifizierung, z.B. Einheiten wie Links zu Unit-Tests oder Freigeben nach Code Review können hier hinterlegt werden (Prio 3). Diese können aber auch in verpartnerten Systemen geschehen, so dass eine Testfreigabe auch en Block ausgestaltet werden kann. (Prio 1)
Delta-Analyse und Skript-Generatoren
Dies Funktionalität kann einen Vergleich zwischen dem Prod-Schema und einen Zielzustand, wie er ggf in Scripts oder einer Referenz-Datenbank vorliegt durchführen und ggf. Skripte zur Synchronisation erzeugen. Dies ist technisch aufwendig und bedarf genauer Kontrolle - im Besonderen wenn komplexe Leistungsmerkmale des DBMS gesucht werden. Mitunter erfordert das ständige Aktualisierung und Qualitätssicherung der Software.
Der Nutzen derartiger Verfahren ist aber dann recht begrenzt, wenn DBDev fachkundig sind und wissen, was sie tun. Ein Derartiges Werkzeug ist dann ggf eine weitere Prüf-Hilfe, aber selten mehr als Nice to Have. Darum nur Prio 4
Roll-Back / Undo von Lieferpaketen
Soll die Funktionalität von Undo unterstützt werden, ist der Kontext entscheident. In HA-Umgebungen kann bis zur Umstellung eine Migration jederzeit abgebrochen werden und erfordert kein besonderes Undo.
In nicht-HA-Umgebungen kann unter Umständen eine Undo ohne Datenverlust nur schwer hergestellt werden. Ggf. müssen Sicherheitskopien der kritischen Tabellen hergestellt werden. Das kann bei großen Datenmengen viel zeit erfordern. Einige Änderungstypen scheinen dagegen mit nur geringem Aufwand Undo-fähig zu sein:
- Grants können jederzeit gewährt oder entzogen werden.
- Neue Spalten können - so lange keine weiteren Datenveränderungen durchgeführt wurden - euch ohne großen Aufwand wieder dropped werden.
- Code-Änderungen bei Views, Trigger oder Stored Prozedures können auch in anderer Version wieder eingespielt werden.
In Produktionsumgebungen soll ein Datenverlust unbedingt vermieden werden. Das Einspielen einer Datensicherung oder eines Roll-Back, wenn die Änderung eine Zeit lang in Produktion gegangen war, führt in der Regel zu unakzeptablen Datenverlusten. Sind die Problem zu groß, dass eine korrektive Aktion erforderlich wird, ist ein automatisiertes Undo zumeist kein Mittel der Wahl.
Aber auch bei Code-Items ist die Feststellung, in welcher Version dieses Element vor der Einspielung vorlag, nicht trivial. Denn zwischen Entwicklungszeitpunkt und Produktions-Rollout können Wochen und Monate vergehen. Patches zur Fehlerbeseitigung können zwischenzeitlich die Stände verändert haben. Ein CM-Inventar auf Objekt-Ebene kann diesen Prozess erheblich unterstützen.
In manchen Situationen ist ein Undo ohne Datenverlust nicht erforderlich: In Test-Instanzen ist der Erhalt genau der gebuchten Transaktionen nicht wichtig, wohl aber die Wiederholbarkeit von Tests. Wenn derartige Funktionen unterstützt werden, muss aber verhindert werden, dass diese leichtfertig in Produktion zum Einsatz kommen. Für diesen Funktionsblock kann je nach Präferenz die Priorität 2 oder 3 vergeben werden.
HA-Unterstützung bei der Erstellung von Lieferpaketen
Wird eine HA-Unterstützung benötigt, können sich Schema-Upgrades bis in die Skriptgestaltung unterscheiden. In der Regel handelt es sich um hoch-spezialisierte Verfahren, die besondere Programmierung und Parametrierung erforderlich machen. Ein Abbruch vor finalem Produktivswitch ist in der Regel problemlos und erfolgreich möglich. Je nach Unternehmenskontext ist Prio 1 bis Prio 3 anzusetzen.
Einerseits dürfte hier erheblicher Aufwand - auch Testaufwand - erforderlich sein, andererseits ist eine HA-Lösung ohne entsprechende Unterstützung kaum vorstellbar. Die Abhängigkeit von Lösungen sind hochgradig an die Eigenschaften der jeweiligen DBMS-Anbieter gebunden.
Roll-Out von Lieferpaketen
Die Ausführung von Lieferpaketen auf der Dev-Umgbung ist für den DBdev im Zuge des Tests erforderlich. Ebenso, wenn Undo-Funktionen unterstützt werden sollen. Der Zugriff auf Schema-Passwords und SysDBA-Passwords ist nicht transparent, sondern wird automatisch aus einem verschlüssletem Bestand heraus durchgeführt. Können diese problemlos auf Dev, nachgewiesen werden, steht einer Freigabe für QA und Prod wenig im Wege.
Berechtigungen, um diese Roll-Outs durchzuführen, werden über das Rollenkonzept abgebildet. Diese Schritte können interaktiv durch Knopfdruk (Prio 1) oder zeitgesteuert (Prio 3) ausgeführt werden. Spezialwissen ist nicht mehr erforderlich, denn sowohl die Lieferobjekte als auch der Rollout wurden ja vorher ausgiebig getestet.
Die Umsetzung kann in folgenden Varianten geschehen:
- Die Anwendung führt direkt einen Connect auf die DB aus, z.B. über JDBC. Die jeweiligen Statements werden dann einzeln submitted. Prio 5 - denn die Risiken, diverse benötigte Features nicht ansprechen zu können, erscheinen zu groß.
- Ein jeweils DBMS-spezifischer Script-Runner (z.B. SQLplus) auf dem zentralen Verwaltungsserver wird adressiert. Die Anwendung steuert diesen. Voraussetzung: Die DB ist von diesem aus erreichbar konfiguriert. Dies ist einfach zu implementieren, ist aber je nach Kontext unzureichend. Je Kontext Prio 1 - 3.
- Es wirf jeweils ein Agent auf den jeweilen DB-Servern lokal gestartet: Dieser führt dann lokal den Script-Runner aus und sammelt Log-Informationen / Fehlermeldungen, die er asynchron dem Server meldet. Dieses Verfahren ist etwas aufwendiger, unterstützt aber folgendes: Wenn die DB exklusiv betrieben wird, also ohne Applikationen und Batch-Prozesse, wird dazu gerne die Listener abgeschaltet. Der Netzkonnect ist dann verhindert, aber benötig einen lokalen Script-Runner. Eine einfache Implementierung kann dann über scp / ssh in Linux-Umgebungen die Steuerung übernehmen. Je Kontext Prio 1 - 3.
Selbstverständlich sind Logginformationen zum Roll-Out-Auftrag zu sammeln und vorzuhalten. Möglichst mit Timing-Informationen, um ggf. Probleme und konkrete Anforderungen genau zu erkennen.
On-Flight-Test
Zu entscheiden, ob eine Schema-Migration erfolgreich war, wird man zuerst durch die Inspektion der Log-Files vornehmen. Dazu muss das Log des Install-Prozesses im System verfügbar sein, also gespeichert werden und per Menü-Funktion erreichbar sein. Da dieses zur Not auch manuell neben dem System geschehen kann, wird hierfür nur eine Prio 2 vergeben.
Erweitert kann automatisiert werden, ob Fehler auftraten. So kann ein grep auf das Logfile mit ERROR oder oder ORA- bereits automatisiert geprüft werden können. Das ergebnis kann mit Gün/Rot signalisiert werden. Ebenfalls Prio 2
Unter Umständen will man aber Funktionstests machen, bevor man die Produktion freigibt:
- Automatisierter Regressionstest - dieser muss natürlich vor dem Rollout vorbereitet und getestet sein. Ein voll- oder halboutomatisierter Aufruf dieses Tests mit Signalisierung des Ergebnisses erhöht die Sicheheit gegen unangenehme Überraschungen. Allerdings ist ein nicht unerheblicher Aufwand je nach Test-Tiefe je Rollout erforderlich. Darum lediglich Prio 3
- Dialogfunktionen könnten fallweise mit Stichprobentests versehen werden. Vor einer Produktionsfreigabe stehen diese aber zumeist nicht ohne Weiteres zur Verfügung. Ggf. sind dann Sonderzugänge zum System erforderlich, und/oder ein Stichprobentest erfolgt unmittelbar nach der Produktivsetzung. Aus Dokumentationssicht wäre es sinnvoll, auch derartige Testdurchführungen manuell zu protokollieren. Ein einfaches Feld, dass diesen Sachverhalt beschreibt, könnte hilfreich sein. Prio 3
Im Besonderen im Kontext einer HA-Unterstützung sollte auch der Test noch vor der finalen Umschaltung erfolgen, denn bis dahin kann man im Kontext von Blue-Green-Schema den Vorgang schadlos abbrechen.
Review von Lieferpaketen
Post Implementation Reviews sind nicht nur sinnvoll nach Produktionsaufträgen, sondern vor allem in den Testphasen. Dies ermöglicht, Schwachstellen und versteckte Fehler zu erkennen. Der Modus des Gesamtablaufes kann durch Objekt-Reviews ergänzt werden. Dies ist in der Regel eine Manuelle Aktion, die in Abstimmung mit mehreren Reviewern geschehen kann.
Das System kann hier nur Dokumentationsfunktionen anbieten. Prio 3
Inventar-Report
Beim Inventar-Report wird weniger an umfangreiche Listen gedacht, sondern um Recherche-Information, um den Stand von Rollouts, dem Paket-Inventar nachvollziehen zu können (Prio 1). Ergänzend kann das Objekt-Inventar, also der Status auf Objektebene, also eines jeden Configuration Items, recherchierbar sein. Diese Funktion unterstützt weitere Planungen, Fehleranalyse und Auditing.
Auditing
Beim Auditing müssten spezielle User existieren, die jeweilige Prüfberechtigungen haben (Prio 2), Prüfaufträge verwalten und Dokumentieren (Prio 3). Der Audit-Report weist dann die jeweiligen Prüfungen und Ergebnisse nach. Auditoren haben allerdings zumeist ein eigenes Instrumentarium. Dennoch bleibt es hilfreich, durchgeführte Audits auch in diesem Kontext zu dokumentieren.
Nicht-Funktionale Anforderungen
Das so skizzierte System erfordert einen sorgfältigen Software-Lifecycle. Mittlere und größere Unternehmen, die in derartige Verfahren investieren, benötigen Investitionsschutz. Also: Die pflege und Wartung des Systems, damit Änderungen, neue Anforderungen und ggf. auftretende Fehler am Roll-Out-System behoben werden können. Der Support kann damit entweder von einem externen Anbieter oder von internen Mitarbeitern gewährleistet werden. In jedem Fall sollte der Code transparent sein. Die Eigentümerschaft am Code muss geklärt sein.
Im Sinne begrenzter Ressourcen kann ggf. auf einzelne Features verzichtet werden. Es ist besser, einen soliden Grundumfang zu realisieren, der großen Nutzen bringt, als sich um jedes ausgefeilte Feature bereits im ersten Wurf zu bemühen. Eine erweiterbare Architektur ermöglicht eine stufenweise Entwicklung. Am Besten ist dann, wenn es sich um unternehmensübergreifende Entwicklungen handelt, wenn eine Plug-In Architektur unterstützt wird. Werden bestimmte DBMS oder Verfahrensvarianten benötigt, könnten diese mit entsprechenden Plugins oder User-Exits umgesetzt werden. Der Kern bliebe dann aber Release-fähig und könnte zentral gewartet werden.
Das durch die beschriebenen Prozesse sensible Unternehmensverfahren betroffen sind, werden Qualitätssicherung und Auditierbarkeit nicht nur der Roll-Outs, sondern auch des Verwaltungssystem erforderlich.
Die technische Umsetzung ist in unterschiedlichen Plattformen möglich. In jedem Fall ist ein RDBMS einzusetzen. Aus Lizenzgründen empfehlen sich Systeme wie PostgreSQL oder MySQL/MariaDB. Im Unternehmenskontext könnten aber Standards (DBA/KnowHow) vorhanden sein, z.B. für Oracle oder SLQ Server, die eine andere Entscheidung vorzüglich machen. Die hier beschriebene Funktionalität sollte auch portable Lösungen ermöglichen.
Ein Element der Modularisierung könnte die DB-Zugriffsschicht sein: Die Datenhaltung könnte je nach Unternehmenspräferenz Oracle, PostgreSQL, MySQL/MariaDB oder SQL-Server sein. Man bräuchte lediglich das Persistenzmodul ersetzen.
Moderne Anwendungsarchitekturen lassen Browser-bedienbare Anwendungen (Intranet) als das Mittel der Wahl erscheinen. Eine Notwendigkeit für einen Fat-Client ist nicht erkennbar. Die Entwicklung derartiger Lösungen lässt sich in allen möglichen Entwicklungsumgebungen realisieren, z.B. PHP, Ruby-On-Rails, Python, Perl, Java oder .NET. Der Unterscheid ist zumeist die persönliche Erfahrung oder unternehmensspezifische Vorgaben: Manche Plattformen sind konzeptbedingt deutlich effizienter als andere, aber das ist nur eine Aspekt, der in einem Unternehmenskontext nicht zwingend die zentrale Rolle spielt. Vor allem die Wartbarkeit der Anwendung hat Priorität.
Eine elegante Umsetzung mit Ruby-On-Rails mag die schnellste Implementierung liefern. Wer aber nicht in diese Technologie investieren will, wird sie nicht für vorzüglich halten. Skript-Lösungen sind für interne Verfahren zumeist attraktiver, denn sie ermöglichen größere Transparenz als aufgebläht komplexe Systeme und damit schnellere Anpassbarkeit. Ein guter Kompromiss kann die Nutzung von PHP sein: Das Know-How ist breit gestreut und im Allgemeinen gut verfügbar.
Systemumgebung und Kontext: Schnittstellen
Neben den unvermeidlichen Schnittstellen zu den unterstützenden DBMS sind folgende Schnittstellen von Interesse:
- Authentifizierungssystem, wie LDAP, Active-Directory o.ä.
- Eine Public Key Infrastructure (PKI), um gesicherte Dateitransfers und remote Calls auszuführen.
- Auftragsverwaltungssystem und Bug-Tracker, z.B. Jira - z.B. via Links
- Versionskontrollsystem (SVN, GIT o.ä.)
- Weitre Configuration-Management Systeme.
- Dokumentationssysteme, Shar Point, Wiki etc.
Die Systemumgebungen sind ggf auch vorgegeben: Server können auf Basis von Linux (z.B. CentOS, Debian etc.) sein, oder auf Windows Servern gesetzt sein.
Fazit: Problemlösung und Umsetzungsstrategie
Verfahrensumstellungen sind zumeist mit deutlichem Aufwand verbunden. Dies erfordert Management-Entscheidungen. Der Aufwand liegt nicht nur in der Entwicklung oder Lizensierung und Betrieb eines derartigen Systems, sondern in der Verfahrensumstellung und Schulung der Mitarbeiter.
Wird das gegebene Verfahren als halbwegs befriedigend erachtet, wird man sich scheuen, in ein neues Verfahren zu investieren. Dies wird genau dann geschehen, wenn
- die bisherigen Verfahren zu viele Probleme verursachen
- Neue Anforderungen - z.B. High Availablility - die bisherigen Verfahren sprengen
- Schnellers Time-to-Market verbesserte Verfahren erfordert
- Kritisches Knowhow (DBA Betrieb) verlagert werden muss.
- Audits und externe Auflagen Verfahrensumstellungen erzwingen.
- Unternehmensreorganisationen neue Verfahren erfordern
- Sinnvolle Angebote zur Problemlösung bestehen.
Gerader letzter Punkt modifiziert die vorgenannten erheblich. Wenn z.B. einer der ersten Punkte eine Motivation zur Verfahrensumstellung liefert, aber keine gangbaren Alternativen bekannt sind, wird man diese Möglichkeiten nicht nutzen. Die Kenntnis der Möglichkeiten alleine wird aber ohne massive Motivation keine Veränderungen der Prozesse bewirken.
Somit versteht sich dieser Text als White Paper um Entscheidungsprozesse zu unterstützen.
Konkreter kann sich die Willensbildung vollziehen, wenn ein Fahrplan zur Einführung erkennbar ist. Ein Commitment der Stakeholder (IT-Management, DBA, DBDev, QA) kann den Prozess ermöglichen, bzw. behindern. Glauben z.B. die Stakeholder, dass sie durch die geänderten Verfahren massive organisatorische oder persönliche Vorteile erfahren, wird sich das in der mehr oder weniger starken Unterstützung der Verfahrensänderung niederschlagen. Innovative Persönlichkeiten neigen zu größerer Aufgeschlossenheit, konservative werden Bedenken gegen Verfahrensumstellungen vortragen. Befürchtet man, dass eine derartige Verfahrensumstellung z.B. den eigenen Job gefährdet, wird man mehr Widerstände erwarten können. Liegt dagegen die Einschätzung so, dass durch die höhere Qualität und Effizienz die eigene Rolle gestärkt wird, und eine drohende Verlagerung vermieden werden kann, wird man Unterstützung erwarten können.
Dies alles führt zu einer bunten Mischung aus Argumenten: In vordergründigen Sachargumenten, in denen die Macher ihre Macht ausüben, kann sich das eine oder andere Motiv verbergen.
Um dennoch vor allem rationalen Entscheidungen Gewicht zu verleihen, ist eine möglichst neutrale Bewertung in Ausgewogenheit anzustreben. Es kann die Strategie sein, die Anforderungen so hoch zu legen, dass die Umstellung zu teuer und undurchführbar wird. Andererseits können zu unambitionierte Anforderungen die Vorteile einer Verfahrensumstellung verschleiern, und sinnvolle Chancen ungenutzt lassen.
Entscheidungsunterstützend kann eine Guerilla-Strategie der Macher sein: In einem Teilbereich werden innovative Lösungen ohne großen Planungsoverhead prototypisch eingeführt, ggf. als Punktlösungen. Diese können bei Gelingen so großen Anklang finden, dass sie auf breiterer Basis zur Einführung kommen.
Der Verfasser ist der Überzeugung, dass sich verbesserte Roll-Out verfahren nicht immer, aber meist zu weit größerem Nutzen als Aufwand führt. Die Probleme, die bei tradiertem und chaotisch gewachsenen Verfahren entstehen, summieren sich oftmals unter der Decke zu Prozessfehlern, einer Unzufriedenheit, erhöhtem ad-hoc-Aufwand und konservativen Verhalten, dass die Funktionsfähigkeit von IT-Abteilungen insgesamt einschränkt und damit weit eher existenzbedrohend wird.