Inhalt
Business Intelligence - Die 2. heimliche Revolution?
Business Intelligence (BI) hat im Moment keinen Hype ... obwohl der Bedarf ungebrochen ist und sich interessante Dinge ereignen. Gemäß dem OLAP-Report wuchs der Markt 2006 um 16,4 %. Beachtlich, jedoch nicht mehr die 40 - 55 % Zuwachsraten, wie sie noch vor 1997 stattfanden. Doch zunächst zur Erklärung:
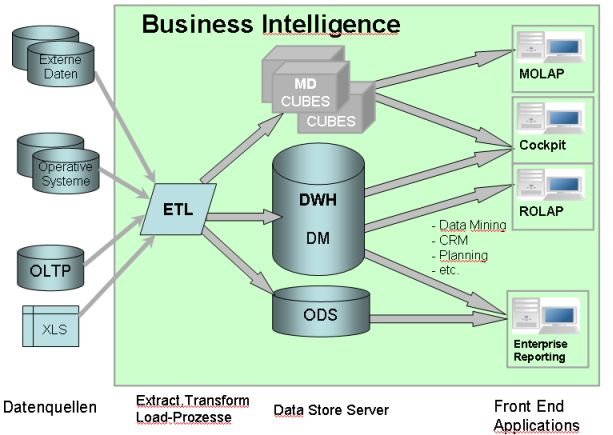
Business Intelligence ist ein eher ungeliebter Sammelbegriff für eine Reihe unterschiedlicher Ansätze und Techniken, die das gemeinsame Ziel eint: Verknüpfte Daten über ein Themenbereich (auch eine Firma) so zu sammeln und aufzubereiten, dass man daraus Erkenntnisse gewinnen kann. Der Begriff ist weniger gebräuchlich für einfache Berichte aus bestehenden Anwendungsprogrammen, sondern umfasst die Bereiche:
- OLAP - Online Analytical Processing: Interaktive Datenanalyse (MOLAP/ROLAP)
- Enterprise Reporting - Standardberichte komplexer Inhalte
- Data Warehouse / Data Marts: Aufbereitete Datenhaltung
- ETL - Extract-Transfer-Load: Datentransferprozesse, Datenmanagement.
- Data Mining, Balanced Score Card, Business Cockpit und andere spezialisierte Anwendungen im Kontext.
Wer braucht sowas?
Sicher nicht der Heimanwender oder Kleingewerbetreibender. Auch sind einige Unternehmensanwendungen mit den Standardreports bereits hinreichend bedient.
Die Zielgruppe für BI-Lösungen ist in diesen Bereichen zu finden:
- Controlling
- Marketing / Marktanalyse
- Unternehmensplanung
- Wissenschaftliche Analysen
In der Regel versuchen Mitarbeiter ihre Probleme mit bekannten Lösungsansätzen zu erledigen. aber diese stoßen an Grenzen
Bottom-Up
Excel oder ähnliche Spreadsheet-Anwendungen haben sich als das Ad-Hoc-Datenanalyse-Werkzeug fest etabliert. Der Siegeszug dieser Klasse hat seine Gründe in dem leicht zu verstehenden Konzept und der Flexibilität für den Endanwender. Es können Daten von unterschiedlichen Quellen eingelesen werden und auf Workbooks kombiniert werden. Mit externen Referenzen und MS-Query können auch Datenbanken integriert werden.
Mit statistischen Funktionen, Look-Ups, Pivot-Tables und Add-Ins lassen sich hervorragend komplexe Anwendungen aufbauen, die an Flexibilität kaum zu überbeten sind. Wo ist der Haken?
Konzeptionell stellen dieses Systeme oft einen ad-hoc Wachstumspfad dar, der auf kurz oder Lang an verschiedenen Ecken hapert:
- Methodenmutation, in der Gruppe: Da es so leicht ist, eine Formel zu ändern, und mal rasch eine Ausnahme zu programmieren, wird es auch getan. Ebenfalls beliebt: Rasch das Worksheet kopiert und mit anderen Varianten weiter gearbeitet. Sowohl die geordnete Datenbewirtschaftung als auch die Transparenz der eingesetzten Verfahren und Versionen geht oft in einem Dschungel von Versionen unter.
- Modellreife: Durch die Methode Wachstum bleibt das Design des Modells oft auf der Strecke. Excel trennt nicht konsequent zwischen Daten und Verfahren. Dies macht die Wartung der Verfahren zunehmend schwieriger.
- Sicherheit: Durch die leichte - auch versehentliche - Änderung können sich im Modell rassch Fehler einschleichen. Es wäre darum erforderlich, mit jeder Änderung das Modell wieder komplett durchzutesten, damit man keine ungewollten Seiteneffeke hat. So wie man es eben bei jedem regulären Software-Release machen sollte. Es wurden zuweilen auch von merkwürdigen Fehlern berichtet, bei der das Modell eigentlich korrekt war, dennoch aber Rechenfehler berichtet wurde ...
- Komplexität: Auch wenn man mit Excel schon sehr umfangreiche Modelle benutzen kann, gibt es gerade in strukturierten Datenflüssen grenzen der Abbildbarkeit. Wenn ein Excel-Spezialist ein hinreichend komplexes Problem bearbeitet hat, kann es meist ein Zweiter nicht einfach mehr benutzen oder gar warten. Die Verifikation und Nachvollziehbarkeit des Modells ist auf dieser Technologiebasis nahezu ausgeschlossen.
- Datenmenge: Excel ist nicht dazu geeignet, große Datenmengen auszuwerten. Datenbestände mit mehreren Millionen Zeilen sind eben nicht drin. Die Verarbeitungszeit nimmt bei komplexen Modellen überproportional zu. Schlicht: Für viele Probleme ist eine reine Excel-Lösung ungeeignet.
- Datenintegration: Die bescheidenen Möglichkeiten von Excel und den Mitarbeitern von Fachabteilungen, reguläre und effiziente Routine-Ladeforgänge und Transformationen durchzuführen, führen zu einem Verlust an Arbeitszeit ...
Darum gehen einige Anwender auch her, mittels MS Access Controlling-Anwendungen zu bauen. Hier kommen wir schon weit mehr in die Gefilde einer klassischen Datenverarbeitung. Denn mit Menüs und Eingabe-Masken, der Trennung von Daten und Verfahren bei reichen Funktionsumfang mit eingebautem Report-Generator und Pivot-Tabellen lassen sich erstaunliche Ergebnisse erzielen. Auch kann Access als Frontend eines richtigen DBMS (mittel ADP) auch eine robuste Plattform für Unternehmensanwendungen sein ... Konzeptionell und technisch ist aber mit der Tool-Wahl aber noch vieles offen und der Raum für Design-Fehler wird größer. Auch empfinden Excel-Anwender hier bereits einen starken Bruch zwischen Access und Excel ... Access kommt als Stand-Alone-Tool auch schnell an seine Grenzen.
Ein anderer Pfad des Bottom-Up ist der über die eingebauten Report-Funktionen eines Anwendungssystemes, z.B. von ERP-Anwendungen. Viele Reports, z.B. im SAP sind bereits stark parametrisiert. Über die Wahl der Parameter ist bereits ein hohes Maß an Analyse-Funktionen gegeben.
Allerdings fehlen oft genug gerade die Auswertungen, die man benötigt. Die Freiheit, eben so eine neue Analyse durchzuführen, geht eben nicht. Auch ist die Zusammenschau von Daten unterschiedlicher Quellsysteme mit dieser Methode nicht möglich.
Anwender aus Fachabteilungen, die dies erkennen, stehen nun unter dem Dilemma: Wenn umfassendere und leistungsfähigere Lösungen im Unternehmen gesucht werden, dann ist der organisatorische Aufwand beträchtlich und das Ergebnis entspricht dem Hornberger Schießen. Oft mangelt es bei der dann gelieferten Lösung an Transparenz, meist jedoch an Flexibilität. Allerdings: Lizenzkosten stellen heute nicht unbedingt mehr eine schwere Hürde dar.
Die erste Blüte
Parallel dazu oder gerade wegen der erkannten Schwächen, haben sich Konzepte und Werkzeuge langsam etabliert, die hier einen deutlich anderen Ansatz unterstützen - Stichworte: Multidimensionalität und Star-Schema.
Mit der Erkenntnis, dass es hier ein neues Paradigma gibt, kam auch der Hype. Von verschiedenen Startpunkten aus bildeten sich Marktführer und respektable Mitbewerber. Von Seiten der Finanzanalysen wurde der Name Hyperion groß, die später mit Essbase, der lange Zeit Nummer 2 im OLAP-Markt fusionierte. Durch Zukauf eines marktführenden Produktes - IRI Express - wurde Oracle mit Oracle Express zum Mitfavoriten. Aus Bereich der Desktop-OLAP Modelle wurde Cognos und Business Objects, gefolgt von Crystal Reports zu beachteten Anbietern. Spezialanbietern in Marktnischen - hier Controlling - verschafften sich eine lokal dominierende Stellung: Applix hatte mit TM1 einen festen Namen, auch wenn der Anteil am Gesamtmarkt nicht auffällig war. Teradata ist gesetzt für Datenhaltung der größten Datenbestände, meist in Verbund mit MicroStrategy, dem Spezialisten für ROLAP. SAS hat als Spezialist für erweiterte Statistiken sein Angebot aus Analyse und Data Mining verstärkt. Informatica wurde der dominierende Anbieter für Datenintegration und ETL-Werkzeuge.
In der letzten Dekade des 20. Jahrhundert setzten bereits Konsolidierungsbewegungen ein. Die Hersteller ergänzten ihre Produktpaletten, um weitgehend zum Full-Liner zu werden und Lösungen aus einer Hand anzubieten. Einige Firmen wurden gekauft und verschmolzen ... der Hype ließ nach.
Multidimensionales Paradigma: Würfel
Die Technologien bleiben ein bunter Mix aus verschiedenen Bereichen, die bei den Lösungen sich ergänzten oder aber Alternativen mit unterschiedlichen Schwerpunkten bildeten. Im Kern hat sich die Erkenntnis der aufbereiteten Datenhaltung in Relationalen Datenbank-Management-Systemen (RDBMS) in Data Warehouses und Data Marts. Als Auswertungswerkzeuge lag das Konzept des OLAP auf relationaler Basis nahe (ROLAP). Alternativ, bzw. ergänzend mit Optimierung auf Geschwindigkeit wurde die Datenhaltung in spezialisierten multidimensionalen Speicherstrukturen (MOLAP) zum festen Bestandteil der Technologiepalette.
Nigel Pendse nennt als Kriterien für OLAP: Fast Analysis of Shared Multidimensional Information — FASMI. Diese sind zur Beurteilung von BI-Lösungen sehr geeignet. So nennt Pendse auch zum Stichwort Fast Zahlen der Orientierung: Die durchschnittleiche Antwortzeit sollte weniger als 5 Sekunden sein, wobei die einfachsten Analysen kürzer als 1 Sekunde und nur weniger Analysen mehr als 20 Sekunden brauchen sollten.
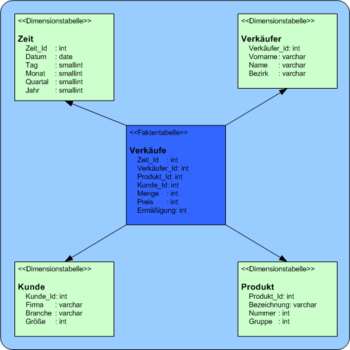
Das Paradigma der Multidimensionalität ist der Würfel (Dice, Cube), der auch mehr als gedachte 3 Dimensionen haben kann. Unter Dimension wird ein Analysekriterium verstanden, wie Produkt/Produktgruppe/Klasse, Kunde/Markt/Region, Zeit ... zu denen die Fakten jeweils zugeordnet sind.
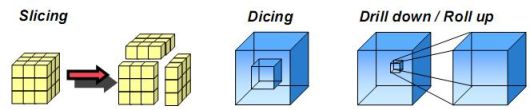
Bei der speziellen Speicherung der Daten in besonders geeigneten Cubes lassen sich vor allem sehr schnelle Analysen und Simulationen realisieren (MOLAP), die vor allem im interaktiven Umgang einer rein Relationalen Lösung (ROLAP) deutlich überlegen ist.
Bei der Modellierung kommt es darauf an, geeignete Dímensionen und Hierarchien zu finden, entlang derer selektiert und verdichtet werden kann. Eine Variante ist z.B. Ist Kennzahl eine eigene abstrakte Dimension, oder sind Kennzahlen eben unterschiedliche Fakten?
Datenintegration - ETL
Meist entscheidet sich der Erfolg von BI-Verfahren in der Verfügbarkeit von zuverlässigen, zeitnahen, vollständigen und leicht zugreifbaren Daten. Die Extraktion der Daten aus unterschiedlichen Quellen, die Transformation in ein geeignetes Schlüsselsystem und angemessene Struktur und das Laden in den zu Analysezwecken bereitgestellten Datenspeicher ist oft die eigentliche Herausforderung für die IT-Verfahren. Die Datenbewirtschaftung erfordert Zuverlässigkeit, Überwachbarkeit (Monitoring), Einbindung in sonstige IT-Betriebsprozesse, Protokollierung, Regeln für den Fehlerfall (Wiederaufsetzen), Wartbakeit des Verfahrens, Revisionssicherheit (Versionierung) uvm. Häufig finden sich spezielle Verfahren und kundenspezifische Skripte, die die besonderen Anforderungen abbilden.
Allerdings ist die Klasse der ETL / Datenintegrationswerkzeuge mittlerweile auch sehr komplex geworden und ermöglicht in vielen Fällen einen starken Nutzen. Als Faustregel gilt weiterhin:
- Bei vielen, auch heterogenen, Datenquellen ist der Einsatz von einem ETL-Tool meist sehr sinnvoll.
- Bei wenigen Datenquellen, aber komplexen Transformationen ist eine individuelle Entwicklung eher von Nutzen, denn der Overhead für einen Werkzeugeinsatz, der zur eigentlichen Problemstellung nicht hinreichend beiträgt, zahlt sich nicht aus.
Der Begriff Transformation ist sehr vielschichtig. Von einfachem Mapping von Quelldatenfeldern auf Zieldatenfelder angefangen wird er über die N:M-Abbildung (Master/Detail etc.) über Bereinigung / Dublettenerkennung, Plausibilisierung / Data Quality, Periodisierung, Aggregierung uvm. verwendet.
Manchmal wird auch von ELT gesprochen. Wenn die Transformation der Daten erst innerhalb der DB, also nach dem Laden, z.B. durch Stored Procedures geschieht. Allerdings handelt es sich in diesem Fall eher um Staging-Tabellen, die noch nicht gleich die Zieltabellen darstellen, und von denen im Transformationsschritt in die Zieltabellen befüllt werden. Ich halte darum eine Unterscheidung zwischen ETL und ELT nicht für hilfreich.
ETL-Tools unterscheiden sich in zwei Grundprinzipien:
- Integrierte Systeme bestehen aus Process-Designer und Ablaufsteuerung (Konsole), weist mit Scheduling. Externe Scheduler, die unternehmensweit eingesetzt werden haben meist ein Interface zu diesem Subsystem. Oftmals bestehen hier Architektonische Ansätze des Hub-and-Spoke: ETL-Prozesse laufen über die 'Speichen' durch eine zentrale Nabe.
- Generator-Lösungen haben ebenfalls einen Process-Designer, erzeugen dann aber Module, die in andere Umgebungen eingefügt werden müssen. Diese Ermöglichen mitunter mehr Flexibilität bei Betriebssystemen und Scheduling Prozessen, die aber nicht immer benötigt wird. Auch Anbieter von Generator-Lösungen liefern zuweilen Integrationsplattformen für die generierten Module.
Namhafte Anbieter von aufwendigen Datenintegrationslösungen sind vor allem Informatica, IBM seit 2003 mit der zugekauften Ascential Enterprise Integration Suite und der neuen Integrationskomponente von Cognos, SAP / Business Objects mit dem ehemals selbstständigen Tool Acta, und Oracle mit ebenfalls übernommenen Toolsets.
Diverse Probleme der Datentransformation und Bereitstellung wurden auf unterschiedlichsten Ebenen diskutiert. Beispiel: Slowly Changing Dimensions: Wenn sich die Dimensionen im Zeitablauf ändern, gibt es in der Regel Abbildungsprobleme. Z.B. Wertpapiere verschmelzen nach Firmen-Merger, Abteilungsstrukturen oder Kundengruppierungen ändern sich ....
Eine wertvolle Quelle zum Austausch über Datenmigration: http://www.datamigrationpro.com/
ETL-Tools können auch verwendet werden, um Aggregate - also Verdichtungen - für den ROLAP-Bereich zu berechnen, um zur eigentlichen Laufzeit nur noch auf den wesentlich kompakteren Datenbestand des Aggregates zugreifen zu müssen. Das ist allerdings nur dort sinnvoll, wenn es eine überschaubare Anzahl von Aggregationspfaden gibt. Soll dagegen jede mögliche Aggregation bereits vorgerechnet werden, kann der Speicherbedarf der Aggregationen den des Ausgangsbestandes übersteigen. Dies lässt sich oftmals auch effizient mit DB-internen Methoden machen, z.B. Oracles Materialized Views, nur sind die Update-Prozesse in die Ladeabläufe einzubinden ...
Ad-hoc Datenmigrationen werden seltener mit Tools durchgeführt, weil leistungsfähige und einfach zu bedienende Werkzeuge standartmäßig nicht zu Verfügung stehen. Durch eine aufwendige Projektentwicklung zur Einführung eines ETL-Tools finden diese auch nicht statt ... vielleicht ändert sich hier einiges durch die Verbreitung lizenzkostenfreier Werkzeuge.
Datenhaltung - Datenbank-Managementsysteme
Daten im BI-Bereich sind häufig sehr umfangreich. Excel-Worksheets kommen meist sehr schnell an ihre Grenzen, und auch MS-Access (MDB) ist für derartige Aufgaben nicht vorgesehen. Die Grundlage der Speicherung von BI-Daten ist ungebrochen ein Relationales Datenbank-Managementsystem (RDBMS). Multidimensionaler Data-Storage kann als sinnvolle Ergänzung im Gesamtablauf gesehen werden, aber ein RDBMS nicht ersetzen. Es geht um robuste Datenspeicherung bis in den mehrstelligen Terabyte-Bereich, gut handhabbares Lade-Management und um hohe Abfrage-Performance. Und bei derartigen High-End-Anforderungen denkt man auch an die Größen im Markt:
- Oracle 10g / 11g
- IBM DB2 - UDB
- Teradata
- Microsoft SQL-Server 2005
- Sybase SQL-Server
In der Tat bieten die Hersteller ihrerseits Leistungen und Funktionen, die speziell auf den Bedarf in Data Warehouses (DWH) / Data Marts (DM) angepasst sind, Star-Queries mit Bitmap-Indexes, Partitionierung uvm. Allerdings schlägt sich der DBA und Anwender oft mit einem Problem: Transaktionsverarbeitung.
Die Meisten Datenbanken wurden für Transaktionsanforderungen (OLTP) konstruiert und mit ausgefeilten Methoden realisiert: Eine Transaktion, also eine Serie von logisch zusammenhängenden, verändernden Schritten werden ganz oder gar nicht ausgeführt - Siehe ACID. Eine schöne Sache, nur hat sie einen Haken: Diese Funktionen kosten Zeit und Platz. Die Transaktionen werden parallel in ein Log geschrieben, damit sie ggf. auch wieder zurück gerollt werden können.
Beim DWH benötigt man diese Funktionen meist nicht, da hier weder ein konkurierender Schreibzugriff zu erwarten ist, noch kritische Transaktionen benötigt werden, sondern nur umfangreiche Ladeprozesse. Dummerweise kann man die Transaktionsverarbeitung bei den meisten o.g. DBMS nicht oder nur unzureichend abschalten. Das wäre nämlich wünschenswert, denn ein abgebrochener Ladeprozess kann durch geeignete Konzepte Restart-fähig sein, ohne sich auf Transaktionen zu beziehen. Zum Teil bieten die Hersteller auch halbherziges Ausschalten der Transaktionslogs z.B. bei Ladeprozessen an, oder aber es werden technische Commits gesetzt (die auch Zeit brauchen), wenn eine gewisse Menge von Schritten durchgeführt worden sind. Bei Stored Procedures oder DB-orientierten Transformationen ist dies mehr als lästig. Jeder Oracle-Profi kennt die Fehlermeldung Snapshot too old, die ein Überlauf der Rollback-Segmente anzeigt. Das, was der Sicherheit dienen sollte, führt durch betriebsbedingte Abbrüche genau zum Gegenteil.
Daher ist es doch nicht ganz so sehr verwunderlich, wenn die Open Source Datenbank MySQL, die nun Teil des SUN-Produktportfolios ist, auch in den DWH-Bereich Eingang gefunden hat. Denn die Datenbank, deren größte Kritik das Fehlen einer robusten Transaktionsverarbeitung ist, kann gerade hierin mit geringstem Overhead brillieren. Es geht also nicht nur um die Total Cost of Ownership sondern auch um Performance und technische Aspekte der Problemlösung. Auch hat SUN ein beachtliches Investment in Sachen Skalierbarkeit von MySQL vorgelegt, so dass für BI auch großer Datenvolumen MySQL als gute RDBMS-Alternative erscheint.
Die Benchmark-Ergebnisse stellen damit nur eine Spitze des Eisberges dar. Benchmarks wie TPC-H werden offensichtlich in jüngerer Zeit nicht mehr so stark unterstützt, bestätigen aber das Bild. Auch hat sich mit Kickfire eine optimierte Hardware/Software-Kombination für High-Performance anforderungen aufgetan, die vor allem kostenbewuste und innovative Entscheider anspricht.
Die erste Revolution: Microsoft
Mit dem Jahrtausendwechsel brach auch der Markt weitgehend um. Microsoft kam mit revolutionären Produkten auf den Markt. Bestechend war nicht nur die konzeptionelle Eleganz, mit der viele Dauerprobleme gelöst wurden, und das Setzen eines neuen Standards der multidimensionalen Abfragesprache MDX - Multidimensional Expressions - sondern auch die bis dahin konkurrenzlos günstigen Preise. Kometenhaft wuchs der Marktanteil.
Im Jahr 2006 beziffert der OLAP-Report Microsofts Marktanteil mit 31,6 %. Dies ging einher mit dem Niedergang der ehemaligen Platzhirsche Hyperion und Oracle. Oracle hat durch falsche Strategie und fehlende Leistung seinen Anteil auf 2,8% heruntergefahren (ohne RDBMS / DWH, vor der Akquisition von Hyperion/Essbase).
Der Charme der Lösung von Microsoft zeigt sich in der beeindruckenden Einfachheit, mit der ehemals nahezu unlösbare Aufgaben konzeptionell und benutzerfreundlich gelöst wurden. Bei SQL Server Analysis Services handelt es sich um einen multidimensionalen OLAP-Server, der im Paket mit dem SQL-Server enthalten ist, aber technisch keineswegs mehr relational aufgebaut ist. Die Benutzung ist auf der Oberfläche klar und einleuchtend dargestellt und verbirgt für den normalen Anwender die Komplexität, die unter der Oberfläche schlummert. Allerdings bleibt diese für den Anwendungsarchitekten kein Geheimnis.
Als Einstieg kann man das Unified Dimensional Model wählen:
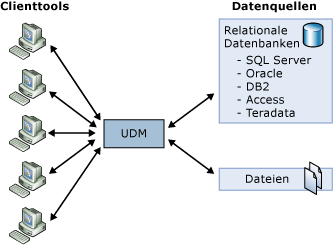
Ausgehend von diesem Grundverständnis nimmt Analysis Services als MOLAP Server die Rolle einer hochperformanten Datenquelle ein. Durch freundliche Administrationsoberflächen, Excel-Connectivity, Data Analyzer, Office Web Components (OWC) oder andere Front-Ends werden die Daten zugreifbar:
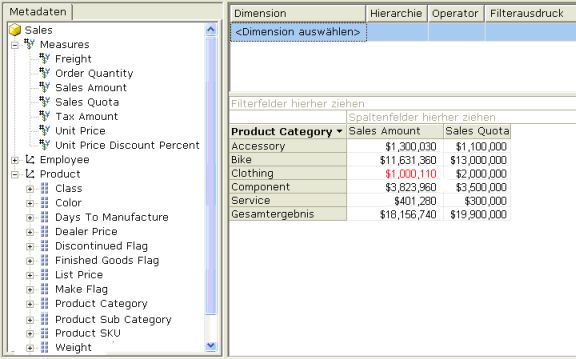
Microsoft liefert gute Dokumentation und Tutorials mit. Ergänzend kann man sich auch gut an den MSDN-Online-Manuals oder Tutorials von William E. Pearson, III informieren.
Bereits in den mitgelieferten Einsteiger-Tutorials bekommt der Benutzer gezeigt, wie mit alternativen, rekursiven und unbalanzierten Hierarchien umgehen kann. Zur Erläuterung:
Das A und O des OLAP-Geschäftes ist, von Detailinformationen zu Verdichtungsebenen einer Dimension zu gelangen. Hierarchieverarbeitung ist Standard. Am besten in definierten Ebenen - das kann auch jeder. Die Probleme beginnen mit alternativen Hierarchien und Verdichtungen. Auch hier haben die Hersteller in der Regel Antworten. Schwierig wird es, wenn die Hierarchieebenen unbalanziert werden, z.B. in einem Ast zwei Hierarchieebenen mehr sind als in einem anderen. Hier brilliert bereits das Microsoft-Konzept von Analysis Services.
Ein weiteres Problem sind rekursive Datenstrukturen - Beispiel: So hat ein Mitarbeiter einen Vorgesetzten, dieser wiederum ebenfalls und so fort. Ob nun eine Firma mehr als 10 Ebenen hat oder mit 4 Ebenen auskommt ... der Rückbezug auf die Datenstruktur bildet die Hierarchie unabhängig von der Tiefe des Baumes ab. Manche versuchen, die rekursive Struktur durch den Aufbau einer konventionellen Hierarchie zu transformieren. Dies leidet oft unter der Transparenz, da die Verdichtung eben auch unbalanziert ist. Auch hier hat Microsoft eine sehr einfache Lösung: Rekursive Strukturen werden ohne Transformation direkt unterstützt.
Mit SQL Server Integration Services ist im SQL-Server neben den Analysis Services - ein multidimensionaler-Datenserver - auch ein vollwertiges ETL-Werkzeug enthalten, dass die Integration unterschiedliche Datenquellen in den relationale und multidimensionale Datenhaltung möglich ist. Und das ohne zusätzlichen Lizenzaufwand.
Dabei kommt Microsoft keineswegs mit einem aufgeblasenen Me-Too-Konzept daher, oder kippt nur eine Oberfläche und Generator über vorhandene heterogene Technologien - so der Oracle Warehouse Builder - , sondern kommt mit einem leistungsfähigen und durchdachten Konzept daher, welches neben einem graphischen Process Designer Betriebsüberwachung, Scheduling, Kontrolle und Logging ebenso liefert wie ein Versionierung der Objekte, Portierung in Produktionsumgebungen und Anschluss an externe Scheduler.
Mit dem Vorläufer des mit SQL Server 2005 enthaltenen Tools, DTS (Teil von SQL Server 2000) konnte ich bereits gute Erfahrungen sammeln. DTS (Data Transformation Services) alleine hätte die Installation des SQL-Servers bereits zu einer wirtschaftlichen und leistungsfähigen Lösung werden lassen. Die Architektur von SSIS:
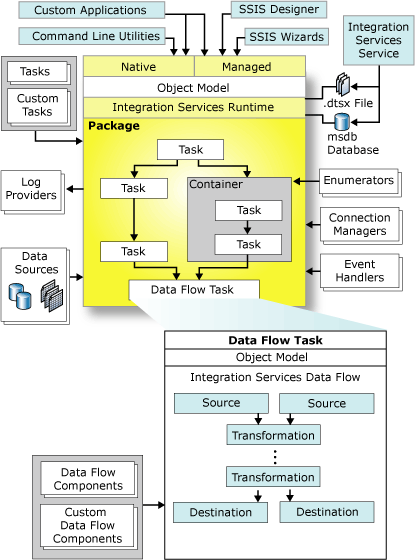
Was hier noch recht komplex aussieht, gestaltet sich im praktischen Betrieb erheblich übersichtlicher. Mit dem Paket-Designer werden auf grafischer Oberfläche aus den Paletten die Datenquellen und Ziele ausgewählt, die Transformationen und Schritte beschrieben und das Modell gespeichert. Dabei wird das SSIS Paket als Objekt versioniert erzeugt und kann direkt ausgeführt werden oder regelmäßig ausgeführt werden. Dieses ist auch von einem externen Aufruf aus möglich, z.B. über einen Command Button in einer Access-Anwendung oder einer Internet-Anwendung.
Debugging und Logging unterstützen Entwicklung und Betrieb. Für komplexe Verarbeitungslogik können Skripte eingefügt werden, also auch SQL-Scripte der Ziel-DB, z.B. Oracle, oder eben solche .NET-Sprachen.
Ein Tutorial ist verfügbar.
... und SAP
Ein weiterer Trend, der weniger von Technologie und Preisen, aber mehr von Business getrieben war ist, der Aufstieg von SAP Business Information Warehouse (BW). SAP Kunden, und das sind ein großer Anteil der namhaften Unternehmen, versprachen sich eine reibungslose Integration erweiterter Analyse-Verfahren mit ihrem führenden Datenbestand. Jeder SAP-Kunde fragte sich also: Warum soll ich nicht eine bereits vorkonfigurierte Lösung meines Standard-Lieferanten wählen?
SAP BW ist in der Regel aus strategischen Gründen das Produkt der Wahl. In einer Umfrage aus 2005 sprachen nur 20 % der Anwender von einer Wahl wegen der Funktionalität. Die Gründe waren hier vielmehr: Unternehmensstandard (49 %) und Einbindung in bereits genutzte Produkte (54%).
SAP hat sein Engagement mittlerweile angepasst. Die gegenwärtige SAP-Strategie heißt nun NetWeaver 2004s BI. Für Nicht-SAP-Experten ist das Angebot nicht leicht zu durchschauen. Die Schnittstellen basieren auf MDX um den zentralen OLAP-Prozessor. Nun spricht SAP auch nicht mer von ODS sondern DataStore Objekten in der Data Warehouse Schicht. Stammdatenverwaltung heißt nun auch zeitgerecht Master Data Management (MDM).
Das erschwert den konzeptionellen Zugang zu Nicht-SAP-Datenbeständen.
Der OLAP Prozessor setzt auf den relationalen Speicher auf (ROLAP). Mit dem BI-Accelerator - einer In-Memory Datenbank, die eine spezielle Hardware von IBM oder HP erfordert - werden hybride Konzepte eingeführt. Ergänzend sind zahlreiche Softwareanbieter mit Datenintegrationswerkzeugen für die Nutzung der Lade-BAPIs des BW zertifiziert.
In der BI-Suite, bzw. Business Explorer (BEx) Suite sind die Applikationen für BI-Anwender zusammengefasst:
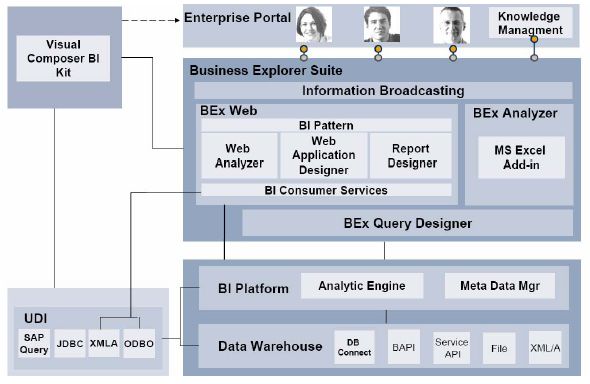
Weitere Anwedungen und Verfahren im Kontext mit BI:
- Data Mining Workbench.
- Strategic Enterprise Management (SEM) / Business Planning and Simulation (BPS) - Jetzt in NetWeaver 2004s BI: „BI Integrated Planning“
- SEM BCS (Business Consolidation)
- SAP APO (Advanced Planner and Optimizer)
- SAP CRM (Customer Relationship Management)
SAP BW läuft auf vielen Plattformen. Wird das BW mit einem SQL Server 2000 (oder folgende) betrieben, können multidimensionale Aggregate in den Microsoft Analysis Services abgelegt werden.
Kurz: Wer SAP in einer umfänglich integrierten Nutzung betreibt, kommt um den Einsatz von BW gar nicht herum. SAP-Anwender, die jedoch nur wenige Kernmodule verwenden, sind auf die Nutzung von BW nicht angewiesen. Wo SAP nicht den dominante Teil der Datenbasis stellt, sind Alternativen sinnvoller Weise zu untersuchen.
Nachdem SAP mit Business Objects (die unlängst Crystal Reports übernommen hatten) in Partnerschaft getreten ist, erscheint die Strategie nicht mehr ganz klar. Die Zukunft wird die Konsequenzen daraus zeigen.
Die zweite heimliche Revolution
Die Trends setzten sich fort. Traditionelle Hersteller wie Cognos, MicroStrategy und Business Objects konnten ihr Angebot so attraktiv gestalten, dass sie von kleinen Schwankungen abgesehen, ihr Niveau halten konnten. Das hinderte allerdings nicht die weiteren Firmenaufkäufe im BI-Markt: Cognos ist nun mit Applix eine IBM-Company, Busisness Objects ist mit Crystal Reports Teil von SAP und Oracle führt nun die Marken Hyperion und Essbase.
Wo sehe ich hier eine heimliche Revolution?
Jenseits der Markanalysen gibt es eine junge Garde neuer Firmen, die den Kundenwünschen in nahezu ungeahnter Qualität entsprechen, und diese mit sehr niedrigen Lizenzpreisen und gutem Service befriedigen. Zum Teil gibt es nun Open Source-Produkte, deren Güte und konzeptionelle Stärke bereits andere gute Konzepte - wie das von Microsoft - in den Schatten stellen. Sicher ist an manchen stellen die Reife bei weitem noch nicht die der etablierten Herstelle, aber die Akzeptanz auch großer Firmen führt zu ganz erstaunlicher Beachtung. Hochpreisige und überladene Produktportfolios mit Unterstützung strategischer Firmenpolitik steht dem Interesse an engagierter punktgenauer Lösung gegenüber, die sich mit innovativen Konzepten und kostengünstigen Ansätzen zunehmend einen wachsenden Platz bei der Menge der Lösungen erobern.

Heraus gegriffen sei hier die Firma Jedox aus Freiburg. Das renommierte Institut Business Application Research Center - BARC aus Würzburg kürte jüngst eine Lösung bei der Quelle AG mit dem Best Practice Award Business Intelligence. Das überraschende bei der Lösung „Business@Times“ für Berichtswesen ist nicht nur die Anwenderfreundlichkeit durch Web 2.0 Ansätze, sondern die Auswahl der Lieferanten und Produkte. Hier setzte man nicht auf große, etablierte Namen, sondern auf dynamische,neue Konzepte, die auch mit einem überschaubaren Investitionsvolunen hervorragende Lösungen erbringen. Jedox lieferte hier überwiegend Open Source Komponenten:
Keineswegs handelt es sich hier um eine Studie oder Kleinanwendung, sondern das Projektteam spricht von 500 täglichen Usern, über 300 davon seien Power-User. Mittels Load-Balancer (F5) werden 6 Web-Server, und mehrere Applikation Server verteit. Immerhin sind auch 1,5 Mio Katalogseiten und Artikelbilder. Man spricht von 35 Terrabyte an Rohdaten. 75 % der Daten werden täglich aktualisiert. Man sieht: hier geht es um richtige Datenverarbeitung. Dennoch kommt das Team mit einem erstaunlich geringen Projektbudget aus.
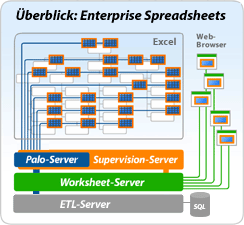
Das ist die Spitze des Eisberges, markiert aber bereits den Wandel. Jedox Lösungen, Spreadsheets von ihren konzeptionellen Schwächen zu entkleiden und ziemlich staight forward ins Internet zu bringen, wird sich kaum in den Marktberichten niederschlagen, denn die Lizenzkosten sind eher vernachlässigbar. Wer die Idee von Microsoft, mit Sharepoint einen hohen Grad von Integration bereits beachtlich findet, wird von der Umsetzung mit den Jedox-Spreadsheet-Servern wahrlich beeindruckt sein. Auch ist die MOLAP-Lösung von Jedox, der PALO-Server, inklusive des Excel Add-Ins lizenzkostenfrei.
Aber Jedox steht nicht als David gegen viele Goliaths alleine. Andere Firmen, die durchaus ein Renommee im Markt erworben haben, unterstützen dieses und ergänzen mit weiteren wichtigen Produkten. Auch Palo wird bereits direkt unterstützt durch Tensegrity Software GmbH, Cubeware, Bissantz ... Eine Unterstützung für Open Office, vergleichbar mit der Excel-Unterstützung ist unter dem Namen PalOOCa''' verfügbar.
Im Besonderen halte ich weitere Produkte für sehr interessant:
- Talend Open Studio v2.3.2 ist eine ausgefeilte ETL-Lösung aus Frankreich (keine Angst, die Website ist auch in English und Deutsch verfügbar), die auch Palo unterstützt. Vertreten in Paris und Nürnberg, und auch in USA, Asien ...
- OLAPLINE ETL: Der Spezialist für Applix TM1, der allerdings auch PALO unterstützt, bietet die Integration mit SAP-Datenbeständen zum Festpreis an (kein Open Source). Es ist nicht mehr die Sorge um Integrationsproblem, die SAP-Anwender in Kompromisse des Hauptlieferanten zwingt.
- Pentaho ist eine Open Source Company, die ein vollständiges Produktportfolio auf Java-Basis bereit stellt. Vertreten in Orlando, Florida, und Borsbeck, Belgien. Die BI Platform besteht aus
- Mondrian - Open Source relationaler OLAP Server - ROLAP - (grob vergleichbar mit Palo - MOLAP)
- Pentaho Reporting Engine - Open Source Reporting
- Kettle - Open Source Data Integration (ETL)
- Dashboards - Cockpit Anwendungen ...
- Weka - Open Source Data Mining
- Pentaho - Comprehensive Open Source BI Suite
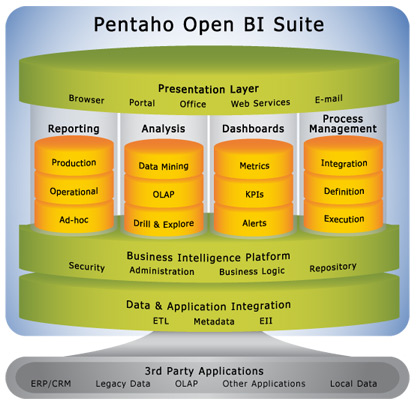
Zu: Talend Open Studio v2.3.2 ist eine als Open Source ETL-Lösung, die sich als Pendant gegen hochpreisige Lösungen von Informatica und andere positioniert.
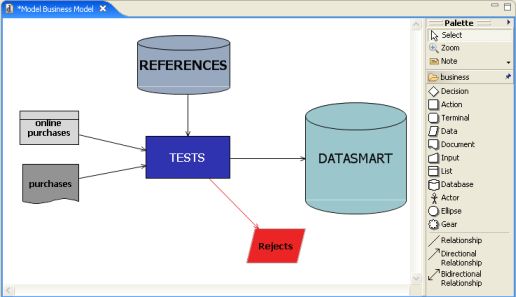
Von der Top-Down-Projektsicht geht es dann zum Mapping:
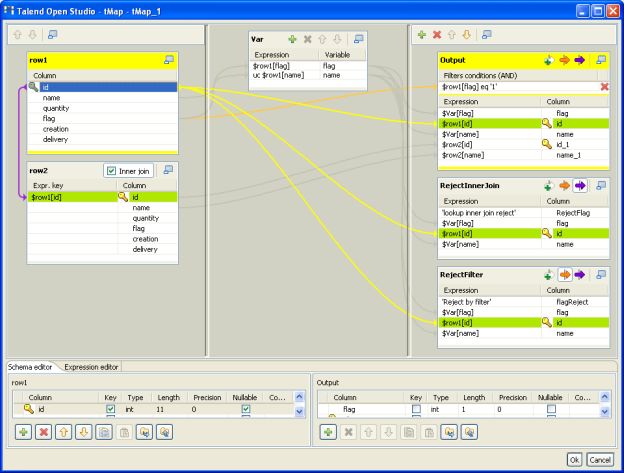
... Beeindruckend ist der Reichtum der Transformationen. Die Component Library enthält über 200 out-of-the-box Komponenten und Konnektoren - einschließlich dem Palo-Server.
Debugging und Tracing, eine Live-Performance-Analyse:
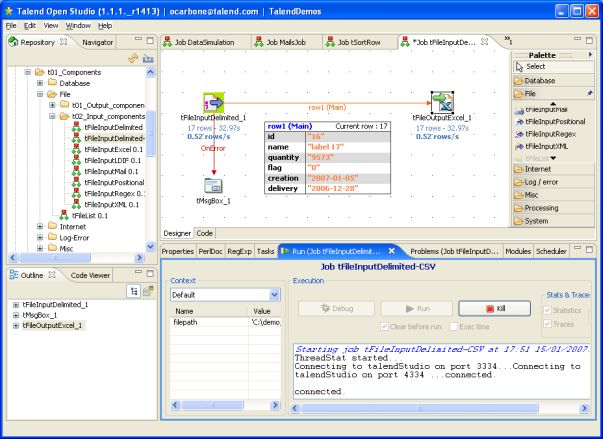
Talends OpenStudio ist eine Generator Lösung auf Java-Basis. Zum Vergleich mit Microsofts Integration Services (Integrierte Lösung): Talend unterstützt mehr Quellen und Ziele, lässt sich leichter in Linux und andere Umgebungen integrieren. Microsoft liefert dagegen eine unerreichte Integration in die eigene Produktpalette mit hinreichender Offenheit für Dritte, die durch eine Konsole und Scheduling auch den Betrieb unterstützt. Dafür bietet Talend seine lizenzpflichtige Integration Suite an.
- Mit Talend On Demand wird hier auch das SOA-Konzept unterstützt!
Fazit: Wir finden leistungsfähige Angebote auf dem Markt, die man anderswo auch für viel Geld nicht bekommt.
Open Source - Ein Geschäftsmodell für BI?
Profis bleiben skeptisch: Open Source ... ist das nicht was für Hobby-IT-Experten? Wir wollen doch professionell Geld verdienen ...
Nun, der Erfolg vieler Produkte, allen Voran LINUX, das von vielen namhaften Firmen genutzt und unterstützt wird, verrät etwas anderes. In vielen Bereichen werden trotz des 'kostenlos'-Image viel Geld mit Open Source verdient. Auch heißt Open Source nicht automatisch 'lizenzkostenfrei'. Auch wenn oft keine Lizenzkosten und die Produkte sich an diverse 'freie' Lizenzmodelle anlehnen, so ist doch häufig mit den Zusatzleistungen Geld zu verdienen. Nur: Der BI-Markt ist meist sehr speziell an größere Unternehmen adressiert, die traditionell zu den Methoden der klassischen Distributionsmethoden neigen, und ein Massenmarkt ist hier auch nicht drin. Somit bleibt abzuwarten, wie erfolgreich dieses Konzept sich im Markt der Business Intelligent durchsetzt.
Hier einige Bedenken und dazu Antworten:
- Open Source-Produkte werden oft unprofessionell gemanaged. Qualität und Commitment passen nicht.
Dies zu erwarten wäre nachvollziehbar, die Realität zeigt ein anderes Bild. Gerade bei Open Source findet sich oft eine dynamische und innovative Software, die hinsichtlich dieser Kriterien viele kommerzielle Produkte übertrifft. Im Besonderen, wenn eine oder wenige Firmen, das Produkt zum Kern ihres Business gemacht haben.
- Open Source-Produkte haben keinen vergleichbaren Reifegrad.
Bedingt richtig. Aber auch kommerzielle Software hat in der Regel Bugs. Ein Beispiel zum Thema Weiterentwicklung:Jedox schreibt zum Palo-Sever 2.0:
- High-Speed Palo Engine (5- 10 fach schneller als Palo 1.5)
- Enterprise Rules - Multidimensionale Formeln für Würfel
- Subsets in Excel
- Geschwindigkeitsoptimierter Export von Würfeldaten
- Open Source-Produkte werden nicht professionell supportet. Auch wird das Produkt nicht weiterentwickelt
Auch hier sind wir im Reich der Legenden. Alle hier genannten Firmen bieten vollumfänglichen Support an.
Dagegen gibt es auch einige Gründe, die Open Source-Produkte attraktiv erscheinen lassen:
- Open Source-Produkte finden Interesse und Vertrauen bei immer breiteren Kreisen der Anwender und Entscheidungsträger. Durch dieses Marketing-Konzept kann man bei entsprechender Qualität auch eine Selbstläufer-Wirkung erzielen.
- Pricing-Probleme bei kommerziellen Produkte: Hat man einen niedrigen Preis angesetzt, wird das Produkt nicht ernst genommen im Vergleich zu Hochpreis-Produkten. Ist das Produkt aber sehr hochpreisig. wird es kaum in die engere Wahl kommen, da dann der Vorteil gegenüber etablierten Produkten nicht mehr offensichtlich.
- Entwicklerdynamik: Durch die Integration auch von Dritten, können auch die Entwicklungsressourcen unerwartet unterstützt werden.
- Add-On Services: Kostenpflichtiger Support, Training, Projekte, Zusatz-Produkte und Beratung ermöglichen einen finanziellen Return.
BI ... Quo vadis?
Auch die etablierten, konventionellen Produkte werden weiterentwickelt und haben in manchen Bereichen ein Lösungspotenzial, das von anderen Lösungen eben nicht erreicht wird. Der Mehrnutzen gegenüber Alternativen übersteigt den Aufwand für Lizenzen oft deutlich. Oder aber, das bereits getätigte Investment in bestehende Produkte soll geschützt werden und nicht durch neue Entscheidungen invalidiert werden.
Entscheider orientieren sich oftmals nicht an Problemen und deren effizienten Lösungen, sondern nach politischen Entscheidungen: Konzernstrategien und Lieferantenauswahl sind oft wichtiger als Kosteneinsparung und optimale Problemlösung. Diese Beobachtungen machte auch Carsten Bange, BARC, in der CW.
Für den Einstieg und Massenmarkt werden Open Source Produkte zur ernsten Konkurrenz. Allenfalls Microsoft bietet durch ihre starke Basis an Office-Produkten und starken, kostengünstigen BI-Lösungen eine ernste Alternative.